

HellaSwag remains one of the most relevant benchmarks in 2025 for measuring commonsense reasoning in large language models. While humans reach 95.6 % accuracy, most open models stay around 80 % and only the strongest proprietary models approach 90 %. The benchmark tests subtle understanding of everyday actions. This is what makes it hard. Unlike trivia or math tasks, commonsense is invisible. Models often miss it. That gap reveals why true understanding remains elusive for AI. HellaSwag highlights this disconnect and has become a diagnostic tool for the limits of current language systems.

What is HellaSwag?
HellaSwag is a dataset and benchmark introduced by Zellers and others in 2019. The goal was to evaluate how well language models can predict what should happen next in real world physical situations. It stands for Harder Endings Longer contexts Low shot Activities for Situations With Adversarial Generations. You can read the original paper on arXiv.
Each item in the dataset starts with a short description taken from video caption datasets like ActivityNet or WikiHow. The model must pick the correct ending from four options. One ending is correct. The other three are designed to be misleading. This is not random. These wrong endings are generated using adversarial filtering. That means they are chosen specifically because weaker models were fooled by them.
The full validation set includes over 10 000 such tasks. Many involve everyday human actions. For example opening a fridge or walking through a doorway. This forces the model to reason about time sequence, physical laws and social norms. These are the areas where large language models still fall short.
HellaSwag is also a test of natural language inference. The system needs to complete a story based on what is implied, not only what is said. That shift makes HellaSwag more robust than older benchmarks like ARC.

Why Commonsense Reasoning Still Fails in AI
Commonsense knowledge is not written down. People pick it up from life. We understand that a person will likely sit before tying their shoes. We know you cannot pour water into a closed bottle. This kind of logic seems obvious to us. But models do not learn it unless it is in the data.
Even with billions of parameters, models trained on the internet often fail at these basic tasks. That is because their training data does not include enough grounded physical actions. It also lacks context about why some things are normal while others are absurd.
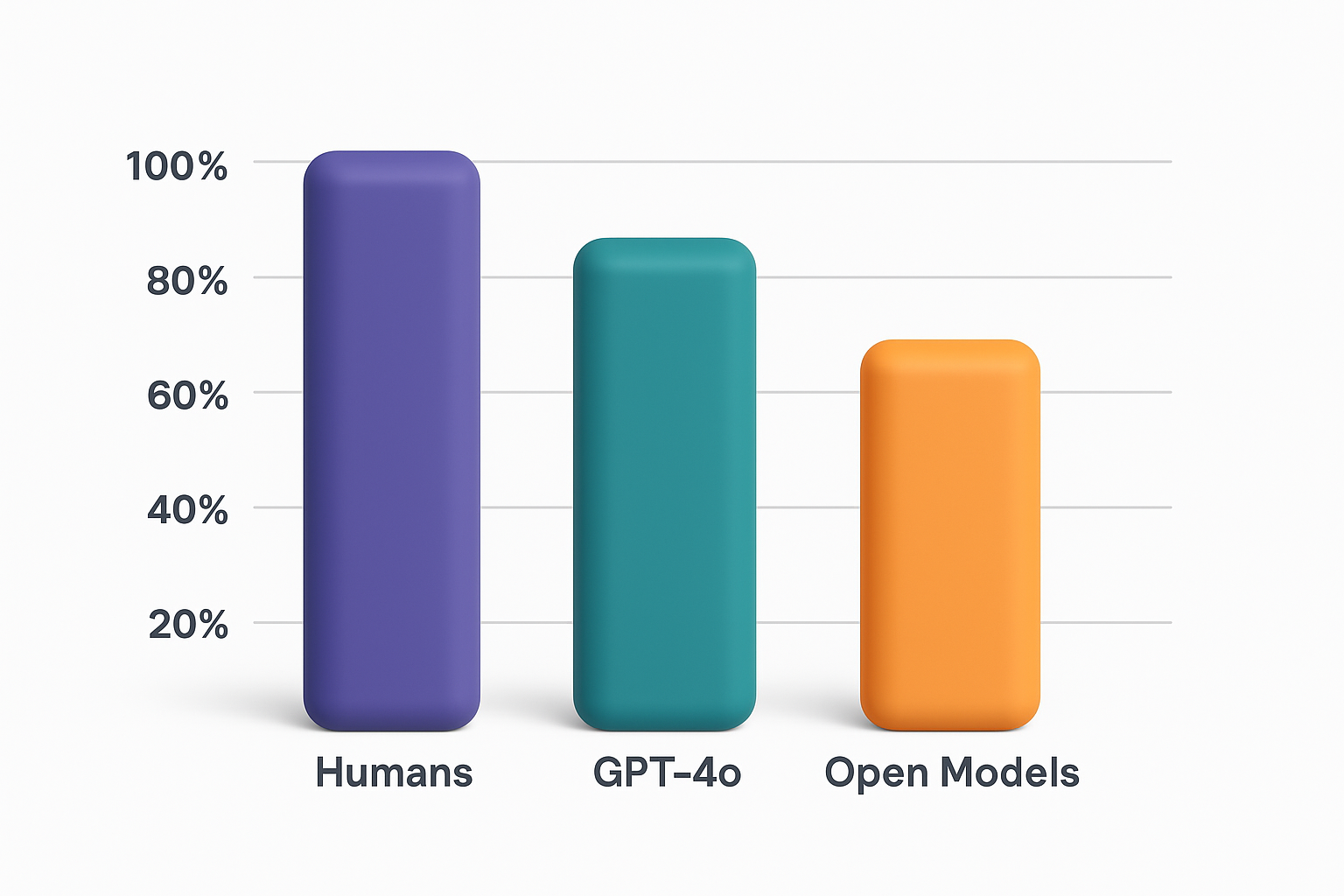
In 2019, humans scored 95.6 % on HellaSwag. Models like BERT and early GPT versions scored under 50 %. As of 2025, top proprietary systems like GPT‑4o approach 90 %, but the average open source model still performs near 80 % (Papers With Code). That gap shows how hard this problem is.
Commonsense is not just a technical feature. It has implications for real applications. For example, in healthcare, legal tech, or autonomous driving, decisions based on missing or faulty logic can be dangerous. HellaSwag helps identify those blind spots early.

How HellaSwag Measures Reasoning
HellaSwag is built to test whether a language model can make realistic decisions about what should happen next in simple, everyday scenarios. Each task in the benchmark starts with a short context. This is usually one or two sentences adapted from video caption datasets such as ActivityNet and WikiHow. These contexts describe physical actions in daily life, such as cooking, walking, or interacting with objects.
The model then chooses the most likely continuation from four possible endings. Only one of these options is written by a human. The other three are generated using adversarial filtering. This process selects incorrect endings that look grammatically correct and plausible but do not match real world logic. These distractors are created by sampling completions from language models and keeping only those that confuse machines but not humans.
Here is an example of a HellaSwag item:
Context: A man opens a box of cereal and starts pouring into a bowl.
- Option A: He places the bowl on the table and grabs a spoon.
- Option B: He throws the cereal at the wall.
- Option C: He walks away and closes the door behind him.
- Option D: He turns the box upside down and nothing comes out.
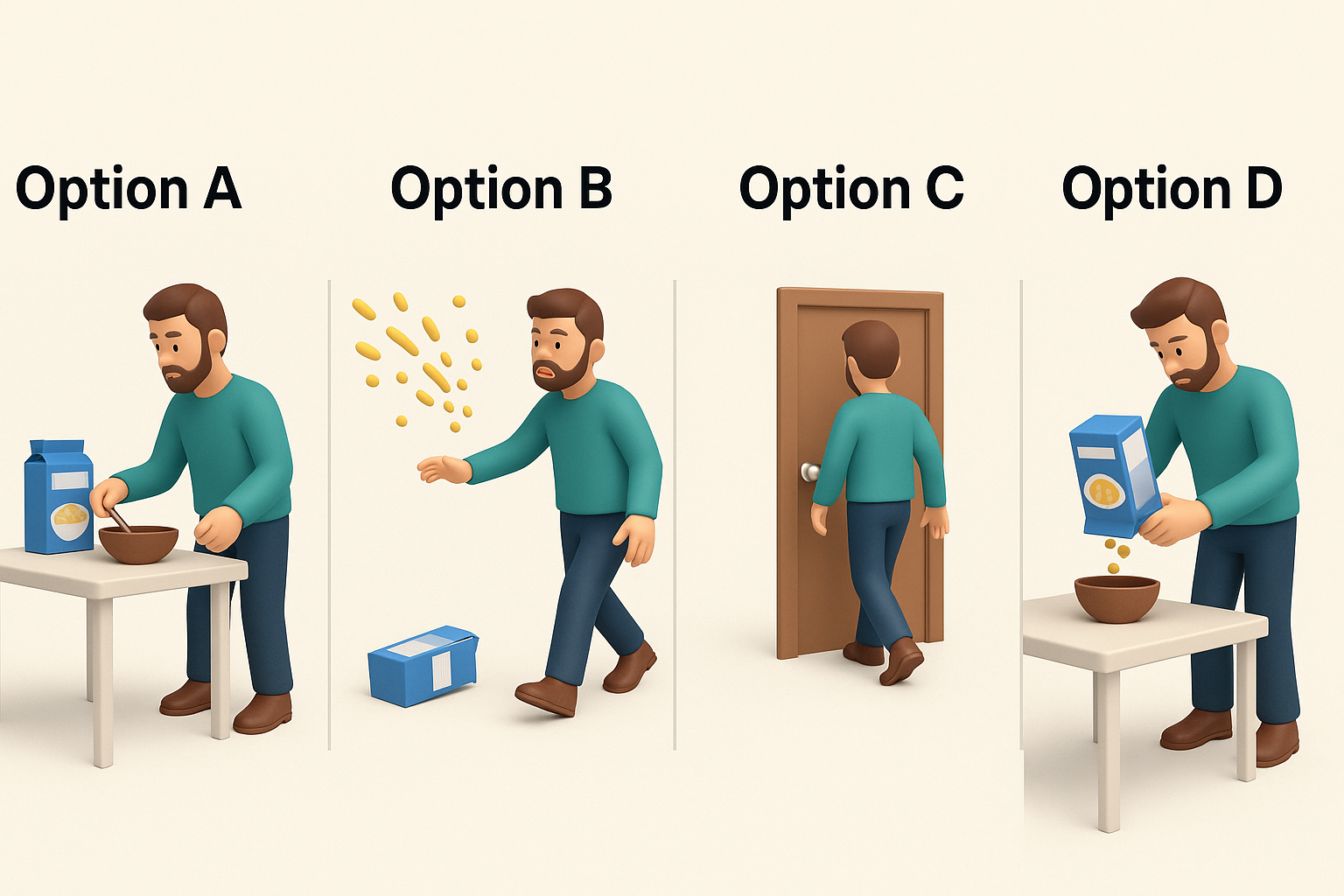
A human immediately sees that Option A is correct. It follows the natural sequence of actions. The man prepares breakfast, then gets ready to eat. The other options may sound grammatical but do not fit the physical or social logic of the situation. A machine must go beyond language fluency and understand the underlying world model.
To achieve this, HellaSwag evaluates reasoning across multiple levels. It does not reward superficial text matching. Instead, it challenges the model to predict what is physically possible, socially acceptable, and temporally coherent.

Performance: Humans Still Win
When HellaSwag was first released, the performance gap between humans and machines was over 40 %. In 2025, it has narrowed. GPT‑4o scores around 88 % to 90 %. Open models like Mistral or LLaMA average about 75 % to 80 %.
But performance varies depending on prompt phrasing, answer order and semantic clarity. Studies show that removing the question prompt still leads many models to select the same answer. That suggests some models rely on superficial clues rather than actual comprehension (arXiv).
There are also known biases. Longer answers are more likely to be chosen. Some items contain grammatical or lexical artifacts that create unintended hints. That limits the reliability of certain samples.
To improve these weaknesses, researchers created GoldenSwag, a cleaned subset of HellaSwag, and HellaSwag‑Pro, a robust multilingual variant with transformed questions across multiple languages and phrasings. You can explore HellaSwag‑Pro in this recent ACL 2025 paper.
What HellaSwag Changed in AI Research
HellaSwag introduced a fundamental shift in how researchers evaluate the reasoning ability of language models. Before its release, many popular benchmarks focused on closed domain question answering. These included trivia tasks, reading comprehension datasets, or multiple-choice exams based on fixed knowledge. While those tests were useful for measuring memorization and language fluency, they were not designed to evaluate whether a model understands context, intention, or physical plausibility.
HellaSwag broke away from this format by focusing on real world inference. The benchmark required models to continue short video-based narratives using only one logically valid ending among several highly deceptive alternatives. This was not just a harder task. It introduced an entirely new category of evaluation: grounded commonsense reasoning.
Following HellaSwag, several new benchmarks adopted its philosophy. Among the most notable are:
- MMLU (Massive Multitask Language Understanding): Tests reasoning across over 50 subjects from high school science to professional law exams.
- Big-Bench Hard: Focuses on deliberately difficult tasks that challenge generalization and logical consistency.
- Social IQa and PIQA: Explore social and physical commonsense respectively, following the same inference-based structure.
Each of these emerged in part because HellaSwag demonstrated that language models needed more than surface-level understanding. Researchers saw that passing basic QA was not enough. What mattered was whether a system could simulate real decisions and predict plausible outcomes.
In 2025, a new milestone arrived. Researchers released HellaSwag‑Pro, a robust extension of the original dataset. This variant included more than 11 000 new question samples across multiple transformation types. These included:
- Rewriting questions using passive voice
- Introducing negation in distractor options
- Paraphrasing correct answers to test semantic sensitivity
- Adding irrelevant but tempting detail
- Varying object references across syntactic roles
- Removing lexical signals that gave away the right choice
These transformations aimed to remove shortcuts and force models to rely on reasoning rather than pattern recognition. All new samples were also validated for grammatical quality and answer clarity by human annotators. The results were published in the Findings of ACL 2025, which confirmed the increased difficulty of the dataset and its usefulness in stress testing advanced models.
As a result, HellaSwag is no longer viewed only as a dataset. It now acts as a methodology for generating new evaluation tools. Its structure has influenced:
- The rise of adversarial filtering as a standard technique
- The use of human validation stages during dataset creation
- The focus on semantically rich and context-dependent tasks in LLM evaluation
More importantly, HellaSwag helped shift attention from raw accuracy to robustness. A model that gets the right answer once may still fail under a paraphrased prompt. The benchmark highlighted this issue and showed that high performance must be stable across variation.
Today, many teams building real-world applications use HellaSwag-style questions during model fine-tuning. This includes conversational platforms, education tools, safety-critical systems, and voice assistants. For instance, platforms built on the Graphlogic Generative AI Platform can incorporate such benchmarks to measure resilience to phrasing and context changes.
In sum, HellaSwag redefined what it means to evaluate language intelligence. It forced the field to confront what models understand versus what they predict. This distinction continues to drive research in model interpretability, alignment, and generalization.
Known Challenges and Biases in the Dataset
Despite its strength, HellaSwag is not perfect. Common issues include:
- Surface artifacts in incorrect answers
- Variance in context length and quality
- Sensitivity to prompt phrasing
- Overlap with training data in some models
- Inconsistent grammar and tone between options
Recent reviews suggest about 36 % of items contain flaws that may bias results (arXiv). This does not mean the benchmark is invalid, but it does call for careful use. HellaSwag‑Pro and GoldenSwag aim to address this by rebalancing, cleaning and validating the dataset using newer guidelines.
Real-World Uses of HellaSwag-Like Testing
Benchmarks like HellaSwag have real product impact. They improve virtual assistants, customer service bots and educational tools. Any AI that responds to humans needs commonsense awareness.
For example, companies building assistants on the Graphlogic Generative AI & Conversational Platform can use benchmarks like HellaSwag to evaluate whether their models choose logical answers in ambiguous settings.
Similarly, tools that transcribe voice input benefit from smarter context inference. The Graphlogic Speech-to-Text API can integrate context aware models trained on HellaSwag‑like reasoning to better understand implied user intent.
Other use cases include:
- Medical bots assessing symptoms
- Home automation reacting to spoken instructions
- Safety systems in self driving vehicles
- Legal summarizers avoiding contradictory phrasing
In all these cases, benchmarks like HellaSwag expose errors before deployment.
Future of Commonsense Benchmarks
Commonsense benchmarks will likely become dynamic and multimodal. This means they will adapt as models improve and include visual and auditory cues. Some early work combines video with text to create fully simulated scenes.
There is growing interest in synthetic environments where models interact and reason about evolving situations. This approach may replace static benchmarks.
Domain specific benchmarks are also growing. Medical commonsense, legal logic and financial behavior all require new datasets with grounded context.
Future benchmarks must also measure consistency, calibration and robustness under adversarial conditions. That is a complex but necessary evolution.
Key Points to Remember
- HellaSwag tests real world physical reasoning through adversarial multiple choice completions
- Human accuracy is around 95.6 %, model accuracy varies from 75 % to 90 %
- It uses video captions and adversarial filtering to generate plausible but wrong answers
- Variants like GoldenSwag and HellaSwag‑Pro aim to improve quality and reliability
Results guide product development in assistants, transcription tools and safety systems
FAQ
It is a benchmark that tests how well a language model can choose the right ending to a short story about everyday life, using adversarial wrong answers.
HellaSwag focuses on physical commonsense and real world situations rather than trivia or knowledge retrieval. It uses adversarial filtering to remove easy choices.
Despite model progress, commonsense gaps remain. Many open source systems fail subtle tasks. HellaSwag reveals those errors better than most tests.
You can try it using the Hugging Face live leaderboard or download the dataset from Papers With Code.
It supports training and evaluation of conversational agents, speech tools, and assistants. It is especially useful in domains where logical errors have high cost.