

In 2025, voice AI is no longer a niche experiment. It is becoming a cornerstone of business automation and healthcare delivery. But moving from pilot to production remains challenging. Deepgram’s Enterprise Voice AI Accelerator program offers a structured method to bridge that gap. In this article I explain how these accelerators work in complex environments, especially in medical and regulated industries. I will share trends, forecasts, tips, and deeper insights you rarely see in marketing texts.

What Is an Enterprise Voice AI Accelerator
An enterprise voice AI accelerator is a structured program that helps large organizations build, test, and scale voice systems with expert guidance. It combines infrastructure, model access, technical coaching, compliance tools, and deployment support. Deepgram’s version gives tailored architecture help, debugging, and workshops so that teams do not stumble over basic integration issues.
Voice AI matters for enterprises because it enables automation of conversational workflows in call centers, telehealth, and internal voice agents. But many companies stall due to scalability, latency, and data security. The accelerator model mitigates those risks by offering a curated path to production.
Why Voice AI Is Strategic for Enterprises and Healthcare
Voice systems let enterprises handle high volumes of speech input with minimal human intervention. In healthcare, voice AI can assist with patient intake, medical documentation, remote monitoring, and even real time alerts. Academic sources in digital health show that speech interfaces reduce documentation burden and increase patient engagement. The Journal of Medical Internet Research has published studies where voice capture improved workflow efficiency in clinical settings.
In sectors such as ecommerce, financial services, and utilities, voice assistants help with user support, identity verification, and proactive notifications. Companies report gains in productivity of up to 30 % when using voice agents for routine tasks. But even strong use cases fail without robust infrastructure and methodological support.

Core Technical and Compliance Challenges
When deploying voice AI at scale, organizations must contend with:
- Acoustic noise and speaker variation: Real world speech includes background noise, cross talk, accents, age variation, health impacts (for example for patients with speech disorders). A voice AI system must reliably transcribe or interpret across these variables.
- Low latency requirements: Users expect near instant responses. Many enterprise systems demand sub-200 ms roundtrip times. That stresses server, network, and model architecture design.
- Custom behavior and control: Enterprises need fine grained control over voice agent personality, domain knowledge, fallback logic, and safety constraints. Generic models do not always suffice.
- Scalability and concurrency: Supporting thousands of simultaneous voice sessions demands elastic infrastructure, load balancing, and often hybrid design with edge or regional components.
- Data privacy, security, and compliance: For regulated sectors such as health and finance, systems must adhere to privacy laws like HIPAA, GDPR, and data residency rules. Encryption, audit logging, anonymization, and secure deployment options (on-prem, private cloud) are essential.
- Governance and risk management: As voice AI integrates with generative components, trust, explainability, and fairness become pressing. The NIST AI Risk Management Framework (AI RMF) offers structured guidance on mapping and managing AI risks. NIST AI Risk Management Framework is a credible anchor for enterprise AI governance.
These challenges are interconnected. For example, enforcing governance slows iteration. Achieving low latency restricts model size or complexity. Thus enterprises need structured support when deploying advanced voice AI.
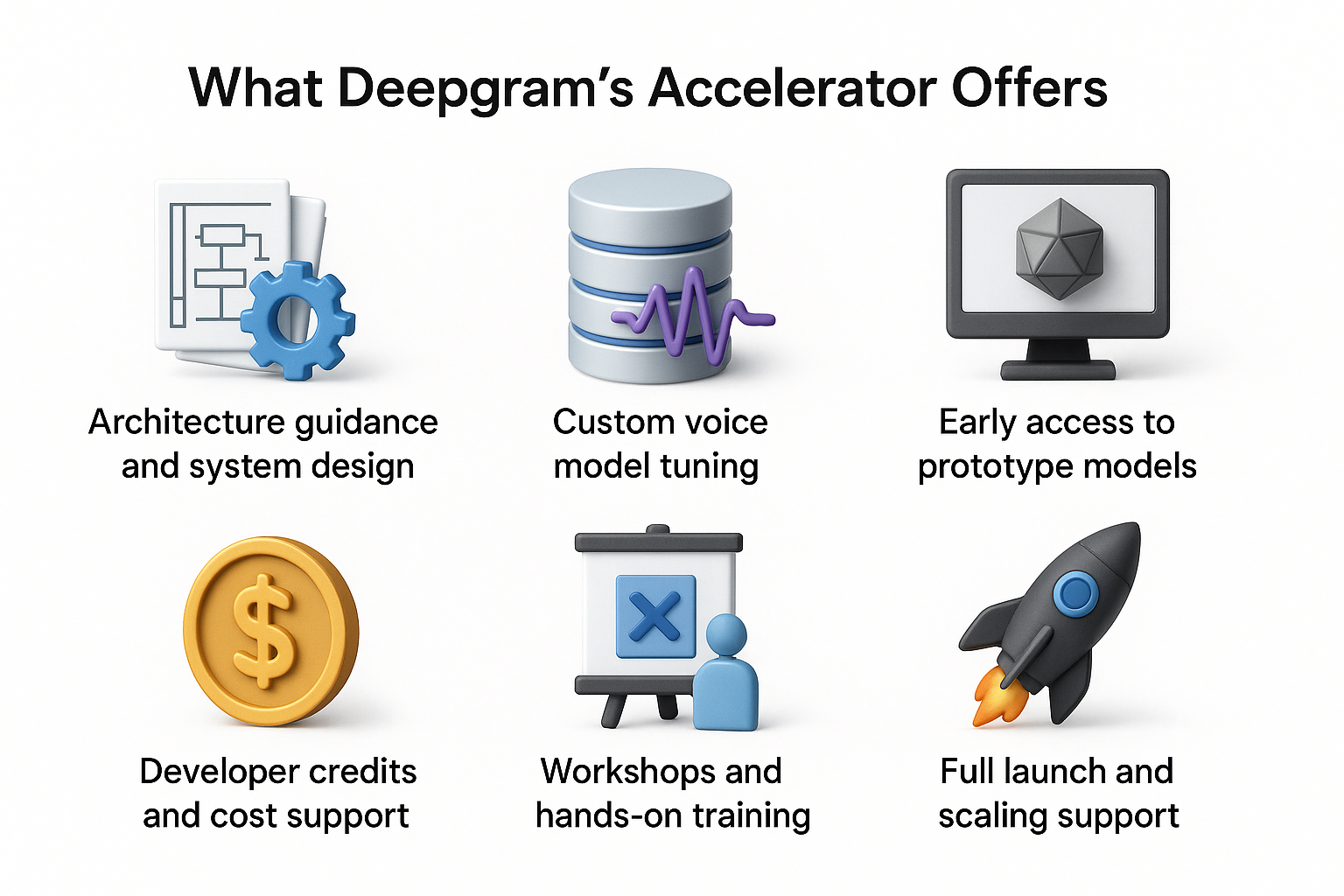
What Deepgram’s Accelerator Offers
Deepgram’s Enterprise Voice AI Accelerator provides a package of services to help enterprise teams move faster and more securely. Key features include:
- Architecture and system design support: Experts help teams choose suitable infrastructure topologies, edge vs centralized compute, streaming pipelines, and fallback strategies.
- Model customization and fine tuning: Deepgram helps tune voice models for domain specific vocabulary, user demographics, accent adaptation, and error recovery logic.
- Access to preproduction and prototype models: Participants gain early access to experimental features or models not yet public.
- Developer credits and cost buffers: The program offers credits that reduce initial cost risk for early exploration.
- Workshops and training: Deepgram hosts hands-on workshops where developers can build prototypes and receive mentoring in voice AI.
- End-to-end launch support: From concept to production, the accelerator assists with integration, tooling, monitoring, scaling, and rollout planning.
One core value is reduced time to market. In some cases organizations in the program have trimmed deployment time by ~30 %. This faster delivery helps demonstrate value sooner and avoid stakeholder fatigue.
Trends and Forecasts in Voice AI and Generative Systems
Trend Block: What’s Next in Voice AI
Voice AI is not static. As generative AI advances, voice agents gain new capabilities. Below are current trends and forecasts guiding the field.
- Convergence with generative models. Voice systems are integrating generative backends so responses are more dynamic, context aware, and less templated. The generative core can fetch knowledge, summarize history, or craft personalized language. Platforms like the Graphlogic Generative AI & Conversational Platform show how text generation and voice interfaces merge.
- Multimodal conversational agents. Voice agents will increasingly support visual or textual fallback. For example in telehealth follow ups, voice may trigger display graphics or charts on a companion app. Agents will fluidly shift between voice, text, and visual cues.
- On-device inference. To minimize latency and preserve privacy, more voice AI computers will shift to mobile or edge devices. This reduces reliance on the cloud and helps with data residency in regulated environments.
- Accent, language, and pathology adaptation. Models will better support regional accents, second-language speakers, and speech affected by disease (e.g. Parkinson’s, stroke). This is especially important in medical and global deployments.
- Privacy preserving audio processing. Techniques like federated learning, homomorphic encryption, and differential privacy will enable model improvements without sharing raw audio. This is critical where raw speech is deemed sensitive.
- Voice biometrics and health signals. Beyond transcription, voice AI will detect health signals (stress, respiratory issues) embedded in voice. Some studies in medical AI are already exploring cough analysis, vocal tremor detection, and breathing under load. In enterprise settings, voice biometric identity could integrate with health checks for remote care.

Forecasts
By 2028, voice AI is forecast to support at least 20 % of customer interactions in regulated sectors like finance and healthcare. According to the AI Index 2024, investment in AI continues to accelerate and technical depth rises. The report highlights that AI in science and medicine is growing fastest among domains. AI Index Report 2024 shows that medical and biotech applications are driving both computer use and algorithmic innovation.
Enterprises that embed voice AI early with robust governance will gain advantage. Programs like Deepgram’s accelerator could play a central role in distributing best practices and diffusion of innovation.
How Enterprises Are Positioned: Adoption and Obstacles
McKinsey’s Global AI surveys show how enterprises currently adopt AI and what performance leaders do differently. In early 2024, 65 % of organizations reported regular use of generative AI. [. . .] This year AI adoption rose to 72 %. McKinsey’s State of AI in Early 2024 details that many firms now deploy AI in two or more business functions. Organizations that lead in AI deploy structured governance, redesign workflows, engage senior leadership and monitor ROI continuously.
Yet many projects stall between pilot and scale. Estimates suggest 85 % of AI proof of concepts never reach production. This is often due to unclear ROI, technical debt, or compliance gaps. In voice AI, the gap is sharper because speech adds real-time, memory, audio, and privacy complexity.
Gartner frames the concept of AI trust risk and security management (AI TRiSM). It demands continuous monitoring, policy enforcement, auditability, and runtime inspection of models. Using AI TRiSM tools helps enterprises maintain compliance and trust. Gartner — AI trust risk and security outlines the shared responsibility model between integrators and vendors.
Given these challenges, the accelerator route becomes appealing. It packages domain experience, validated architecture, and governance tools. Enterprises reduce reinvention and avoid pitfalls.
Practical Tips and Rare Details for Deployment
Here are actionable tips and lesser known insights for teams launching enterprise voice AI:
- Segment by use case complexity. Start with low risk tasks (e.g. FAQs, data retrieval) before voice control of critical systems. This phased approach limits exposure.
- Use adaptive fallback logic. Never rely fully on one model. Build fallback strategies (e.g. confidence threshold routing to human, hybrid models) to catch errors gracefully.
- Monitor voice error drift. Speech models degrade over time with evolving accents, device changes, or firmware updates. Track word error rate (WER) over segments and retrain periodically.
- Instrument analytics per utterance. Log confidence scores, latency per segment, retry counts, session duration. These details expose patterns invisible at aggregate level.
- Balance model size vs latency. Use distillation, quantization, or pruning if inference latency is too high. Sometimes a slightly smaller model with lower latency yields better UX.
- Design safe prompt filtering. Even voice systems invoking generative backends need filters to avoid harmful or hallucinated content.
- Use synthetic noise augmentation. In training data, inject realistic audio noise, cross talk, and channel distortions to make models robust to field conditions.
- Plan privacy by design. Minimize stored raw audio, use anonymization, and avoid voice profiling unless absolutely justified and consented.
- Benchmark per locale and language. Never assume one model suffices across regions. Accent, dialect, audio hardware differences demand locale specific tuning.
- Integrate domain knowledge modules. For medical deployments embed clinical vocabulary, terminologies (ICD, SNOMED), and constraints to reduce hallucinations.
These tips reflect lessons from real voice AI deployments in sensitive industries.

How to Integrate Graphlogic APIs Seamlessly
Integrating Graphlogic APIs into your voice AI ecosystem is a practical way to connect speech input, processing, and output without rebuilding your infrastructure from scratch. Many enterprises already use this approach to layer advanced generative and voice capabilities into existing customer service, telehealth, and workflow automation systems.
Step 1: Establish the Speech Layer
Start with the Graphlogic Speech-to-Text API. This API converts spoken input into structured text that can be processed by your core AI logic. It supports multiple languages and is trained to handle variable audio quality, background noise, and diverse accents.
You can deploy it in two modes:
- Real-time streaming, where the system transcribes speech as it happens for live interaction scenarios such as customer support or patient consultations.
- Batch processing, where recorded audio (for example call logs or dictations) is transcribed asynchronously for documentation or analytics.
For healthcare and regulated environments, it is important to configure encryption at rest and in transit, and to route data through compliant storage options. This step ensures that no identifiable audio remains unprotected.
Step 2: Connect Generative Logic for Dialogue Management
Once transcription is stable, connect it with the Graphlogic Generative AI & Conversational Platform. This layer manages context, intent recognition, and dynamic response generation. It combines natural-language understanding with retrieval-augmented generation (RAG), which means it can access and synthesize up-to-date information securely from enterprise databases.
In practice, this setup lets your voice system:
- Generate personalized, context-aware answers to user queries.
- Retrieve real-time data such as appointment availability, inventory status, or lab results.
- Adjust tone and response complexity to the conversation context.
The platform can operate through APIs or SDKs, making integration straightforward for engineering teams already familiar with REST or WebSocket protocols.
Step 3: Return Voice Output
After generating a text response, you can use a Text-to-Speech (TTS) engine or avatar system to convert it back into natural voice. The Graphlogic ecosystem also supports TTS and avatar endpoints, so you can maintain consistent quality across the entire pipeline. Some enterprises link these components through unified middleware, ensuring that latency stays under 200 ms for conversational flow.
For complex deployments, the accelerator guidance helps you tune model pipelines and caching logic so that speech recognition and generation operate in parallel. This minimizes round-trip delays even under heavy load.
Step 4: Manage Latency and Quality
A frequent challenge in large-scale voice AI deployments is response delay. To optimize latency:
- Deploy speech processing close to the user location (edge or regional cloud nodes).
- Use asynchronous streaming where possible, allowing output to begin before transcription completes.
- Cache frequent requests and responses, especially for high-volume support scenarios.
- Continuously monitor average response time per session and flag any drift above your service-level threshold.
Graphlogic APIs are designed for concurrent workloads, so enterprises can manage thousands of sessions without degraded performance if architecture is planned correctly.
Step 5: Implement Fallback and Safety Logic
Even the best models can fail when encountering unexpected accents, domain terms, or user phrasing. A well-designed voice AI pipeline always includes fallback logic. For example, if confidence in transcription drops below a set threshold, the system can automatically prompt clarification or switch to a human agent.
Within the generative layer, safety filters should screen output for sensitive or inappropriate content. You can use moderation APIs or custom rule sets to prevent unexpected language or disclosure of restricted information.
Step 6: Maintain Continuous Learning and Compliance
Once the system is live, continuous retraining is key. Monitor logs for word error rates, latency distribution, and user satisfaction. Periodically retrain models with anonymized real-world audio samples to improve robustness.
For regulated domains such as healthcare, audit trails and access control lists are essential. The U.S. Department of Health and Human Services outlines privacy safeguards in the HIPAA Security Rule. Aligning with such frameworks ensures that your voice AI not only performs well but also stays compliant over time.
Step 7: Scale Gradually and Test Extensively
Before global rollout, test the integration in controlled environments. Evaluate system behavior under noisy conditions, varied accents, and multi-speaker overlap. Record latency and accuracy across devices (mobile, desktop, kiosk).
Once validated, scale region by region with automated deployment scripts. Use metrics dashboards to watch throughput and resource use in real time.
By combining the Graphlogic Speech-to-Text API for precise input capture and the Graphlogic Generative AI & Conversational Platform for natural, dynamic dialogue, enterprises can build conversational systems that rival human responsiveness while maintaining data security and operational control.
This integration pattern aligns with the principles of programs like Deepgram’s Enterprise Voice AI Accelerator, which emphasize modular architecture, low latency, and compliance-ready deployment. For enterprises in healthcare, finance, and large customer service networks, this combination represents one of the most practical and scalable ways to bring advanced voice AI into daily operations.

How to Apply for and Use Deepgram’s Accelerator
The Deepgram Enterprise Voice AI Accelerator is open to organizations that are ready to move beyond experimentation and bring voice or conversational AI into large-scale production. The program is designed for enterprises that already have an identified use case — whether it’s automating customer support, streamlining medical dictation, or building intelligent voice-driven analytics — and need a structured framework to scale efficiently and safely.
Application Process
To apply, companies submit a project plan detailing their current stage, technical goals, and anticipated business impact. The application should include:
- Key objectives and measurable outcomes.
- Data capacities, such as available voice datasets and labeling infrastructure.
- Compliance and security constraints, especially for regulated industries like healthcare, finance, or government.
- Technical readiness, outlining existing AI infrastructure or APIs in use.
After review, selected participants enter a structured onboarding phase, during which Deepgram’s specialists align on architecture, define milestones, and identify potential bottlenecks.
Program Benefits
Accepted enterprises gain access to a suite of resources that combine technical, strategic, and operational guidance:
- Architecture and optimization support for integrating Deepgram’s APIs and SDKs into existing systems.
- Workshops and labs focused on speech model tuning, latency optimization, and compliance design.
- Credits and infrastructure allowances to accelerate proof-of-concept and production deployment.
- Mentorship and partner sessions with Deepgram engineers, solution architects, and industry experts.

Commitment and Timeline
Participation requires dedicated internal resources — developers, data engineers, compliance officers — to ensure integration success. Teams are expected to:
- Prototype and iterate actively.
- Integrate user and system feedback.
- Report progress and refine architecture as the program advances.
Each cohort typically runs for 6 to 12 months, featuring clear benchmarks, technical milestones, and periodic assessments. These checkpoints help teams measure ROI, adjust implementation strategies, and accelerate time-to-production.
By the end of the program, companies emerge with a validated, scalable, and compliant voice AI solution — ready for real-world deployment and expansion across multiple workflows and markets.
Final Thoughts
Voice AI is evolving fast. Its integration with generative AI, better privacy methods, and edge computation will accelerate adoption. For enterprises, success depends on not just models but robust architecture, governance, and deployment strategy. That is what voice AI accelerators aim to provide. Deepgram’s program is a credible pathway for enterprise teams to avoid common pitfalls, gain expert support, and scale voice AI reliably.
FAQ
A voice AI accelerator is a structured support program that combines expert guidance, infrastructure, model access, and training. Enterprises in regulated sectors, health, finance, retail, or support operations will benefit most when voice AI exceeds pilot scale.
Costs vary by provider and scale. Many accelerators offer credits or subsidies to reduce risk. The real cost is internal staff time and integration effort. The goal is to de-risk and lower total cost.
Yes but only with careful architecture. Use encryption, anonymize data, restrict audio storage, and separate PHI (protected health information). On-premises or private cloud deployments are safer. Always run external audits and governance reviews.
Track metrics like call deflection, average handling time reduction, first contact resolution, error rate, and user satisfaction. For healthcare, measure clinician time saved, documentation reduction, or response times.
Yes if models are trained on representative noisy data and use robust audio processing. Use noise suppression, beamforming mic arrays, and fallback logic. Some systems degrade gracefully by converting to text-only mode.