

Automatic speech recognition, or ASR, began in 1952 when Bell Labs created Audrey, a system that could recognize digits from zero to nine. It was limited and slow, but it proved speech could be processed by machines. This article looks at how ASR grew from those early experiments into today’s deep learning systems, and why its history helps us understand current challenges and future directions.

Statistical Breakthroughs of the 1970s
The 1970s changed ASR forever. The introduction of Hidden Markov Models (HMMs) allowed computers to analyze phonemes statistically. A phoneme is the smallest unit of speech. By computing probabilities of sequences, HMMs increased recognition accuracy significantly.
Engineers soon combined HMMs with noise reduction techniques to improve real world usability. HMMs became the standard method of acoustic modeling and influenced much of the research that followed. This marked the move from digit recognition to continuous speech recognition.
The Role of Language Models
By the late 1970s and 1980s, language models entered the scene. The trigram model predicted the likelihood of a word based on the two words before it. This gave machines the ability to use context rather than isolated sound analysis.
The trigram model influenced nearly 80% of ASR systems worldwide. It also powered early consumer devices. Even today, assistants like Siri and Alexa rely on descendants of these models.
Beam search algorithms further improved accuracy by considering multiple possible sequences and choosing the most probable one. This made speech recognition less rigid and more humanlike.
More information on probabilistic models can be found in Nature.
Neural Networks of the 1980s
The late 1980s introduced neural networks into speech recognition research. These networks could learn from large amounts of data and identify complex patterns. They improved phoneme differentiation and reduced mistakes between similar sounding words.
Companies adopted neural network powered ASR in customer service environments. Call centers used it to automate simple queries. However, this came at a cost. Systems required more computational resources than many enterprises could afford.
This was the first glimpse of machine learning driven ASR. While expensive, it was clear that neural networks would shape the future.

Deep Learning and End to End Models
The 2010s brought the era of deep learning. End to end models now process raw audio directly into text. This replaced the older pipeline of separate modules for feature extraction, acoustic modeling, and language modeling.
With the help of massive datasets, deep learning models improved accuracy across multiple languages and accents. They also managed noisy backgrounds more effectively. High performance GPUs enabled large scale training, driving down error rates while maintaining speed.
For enterprises, this meant transcription could finally be accurate, scalable, and cost effective at the same time. Providers such as Graphlogic Speech to Text API show how modern ASR adapts to different business scenarios.
Consumer Adoption in the 2000s and 2010s
Widespread adoption began less than 15 years ago. Google Voice Search was one of the first consumer tools. Then came Siri, Alexa, and later assistants integrated into phones, smart speakers, and vehicles.
Today, millions of people rely on ASR daily. Voice commands control homes, search engines, and mobile devices. This would not have been possible without decades of progress in language models, noise filtering, and deep learning.
The role of ASR in consumer life is now as essential as touchscreens or keyboards.
Enterprise Uses and Analytics
Enterprises use ASR for much more than commands. It now supports transcription of meetings, multilingual communication, and advanced analytics.
Customer service benefits from emotion and sentiment detection. Call centers use ASR to measure customer satisfaction in real time. Automated voicebots reduce wait times and improve efficiency.
Integration with AI platforms allows businesses to extract insights from speech data. For global companies, multilingual support is essential. Modern systems can transcribe in many languages with high accuracy.

Persistent Challenges in ASR
Despite progress, challenges remain. Noise is one of the most persistent issues. Busy environments reduce accuracy. Even the best beam search algorithms can confuse homophones.
Another challenge is cost. Deep learning systems demand massive computational resources. Training state of the art models consumes megawatt hours of electricity. This raises sustainability and accessibility concerns. Smaller enterprises cannot always afford such infrastructure.
Language diversity is another problem. Models trained mainly on American English often fail with African or Indian English. Dialects and accents are harder to generalize, which affects accuracy in global deployments.
Comparative View of Generations
Looking at ASR history shows how each generation built upon the last.
- The 1950s focused on digits with rule based systems
- The 1970s and 1980s introduced HMMs and trigrams for phoneme recognition
- The late 1980s added neural networks, increasing accuracy but demanding more power
- The 2010s and beyond rely on deep learning and end to end systems
Each stage solved earlier problems but introduced new limitations.
Trends and Forecasts
ASR is increasingly tied to conversational AI. Future assistants will engage in multi turn dialogue with context awareness. They will not just transcribe speech but also interpret intent.
Transformer architectures already outperform older recurrent neural networks. They handle long sentences more efficiently and with fewer errors. Optimized versions are reducing computational costs, making them practical for real time use.
Another forecast involves multilingual and dialect support. Companies are investing heavily in this area to serve global users. This includes adaptation to slang and local speech patterns.
Platforms like Graphlogic Generative AI and Conversational Platform highlight how speech recognition is merging with natural language understanding. The result is an ecosystem of intelligent voice applications that extend beyond simple transcription.
Experts predict that by 2030 the global ASR market will exceed $50 billion. Growth will be driven by enterprise adoption, healthcare transcription, and AI powered customer service.

Practical Advice for Businesses
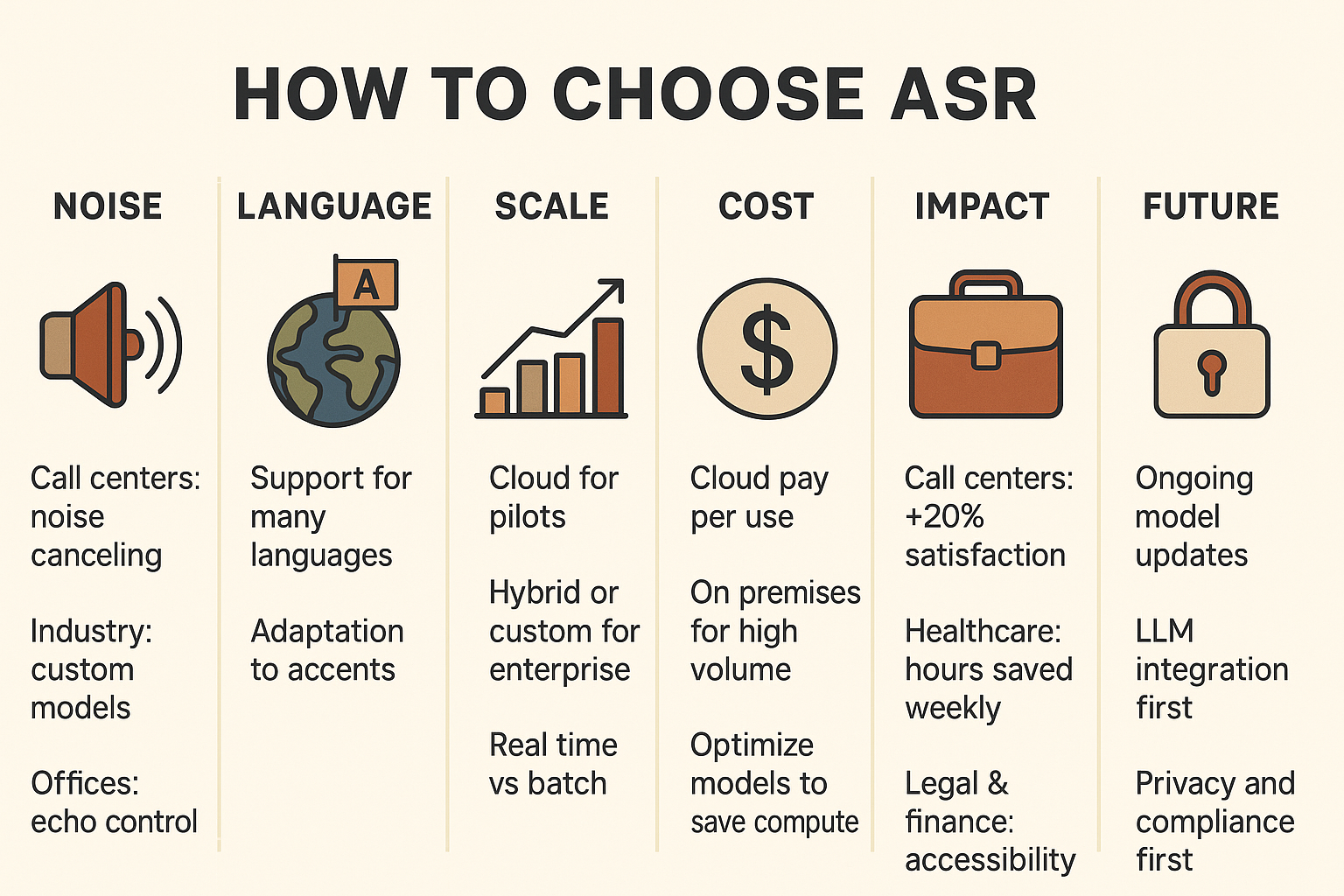
When evaluating and implementing an Automatic Speech Recognition (ASR) solution, companies should take into account a variety of technical, operational, and strategic factors.
Noise Environment
The reliability of ASR systems depends heavily on the acoustic environment.
In call centers, background chatter and line noise can reduce accuracy; noise-canceling front ends or domain-specific tuning may be required. In industrial settings, machinery and ambient sounds can overwhelm generic ASR, making specialized models or microphone arrays more suitable. In quieter offices or healthcare facilities, accuracy tends to be higher, but echo cancellation and speaker diarization (distinguishing between speakers) remain important.
Language and Accent Support
Businesses serving diverse markets must ensure their ASR solution covers the range of languages and regional accents of their customers or employees. Global enterprises often need multilingual transcription (e.g., English, Spanish, Mandarin). Accent robustness is critical: a system trained on U.S. English may underperform with Scottish or Indian English unless accent adaptation is supported.
Scalability and Workload Size
Small teams or pilots benefit from cloud-based APIs, which are cost-effective and easy to integrate, reducing deployment overhead. Enterprise deployments with millions of minutes of audio per month may prefer in-house or hybrid approaches with custom training to reduce costs and improve domain accuracy. It is also essential to consider whether real-time transcription (low latency) or batch processing is required.
Cost of Computational Resources
ASR requires substantial compute for training and inference. Cloud services shift costs to a pay-per-use model, which is beneficial for sporadic usage. On-premises solutions require upfront investment in GPUs/TPUs but may pay off for high-volume tasks. Optimization strategies like model quantization and streaming recognition can reduce compute demands.
Business Impact by Industry
In call centers, ASR can improve customer satisfaction scores by over 20% by enabling real-time agent assistance, compliance monitoring, and sentiment analysis. In healthcare, it reduces physician documentation burden by several hours per week, freeing time for patient care. In legal and finance, accurate transcription accelerates compliance audits, discovery processes, and multilingual negotiations. In media and entertainment, ASR enables captioning, subtitling, and content search, increasing accessibility and audience reach.
Future-Proofing
It is important to look for vendors with continuous model updates, especially as ASR technology rapidly improves with foundation models. Businesses should also consider whether their provider supports integration with LLMs for summarization, entity extraction, or analytics on top of transcripts. Finally, data privacy and compliance (HIPAA, GDPR) should remain central considerations depending on the industry.
Rare Details Worth Knowing
One lesser known fact is that early ASR systems in the 1960s could only recognize single speakers. Multi speaker recognition was considered impossible until the late 1980s.
Another detail is that the first commercial speech recognition products in the 1990s cost over $9,000 and required training for each user. Today, free voice assistants in smartphones offer better accuracy than those systems ever achieved.
Environmental impact is also under research. Training large ASR models can emit several tons of carbon dioxide. This has sparked interest in efficient architectures and green AI initiatives.
Why This Evolution Matters and What To Do Next
The story of automatic speech recognition from 1952 and the Audrey system to today’s deep learning based assistants shows how far voice technology has come. Each stage improved accuracy, speed, and usability. At the same time, new challenges emerged. Businesses and individuals who want to use ASR today should learn from this history and apply it to real decisions.
What It Means for Businesses
For companies, the value of ASR is not only about converting speech into text. It is about saving time, cutting costs, and gaining insights. In customer support, using ASR for automated transcription can reduce the time agents spend on documentation by up to 40%. Call centers using sentiment analysis powered by ASR report improved customer satisfaction scores of over 20%. In healthcare, doctors using ASR tools save several hours per week on patient notes. This time can be spent with patients instead of keyboards.
Cost remains a concern because deep learning models require powerful GPUs and large amounts of electricity. Enterprises should weigh cloud based APIs against custom in house deployments. APIs such as Graphlogic Speech to Text API help businesses scale quickly without heavy infrastructure. For long term strategies, investing in more efficient architectures and monitoring energy consumption can lower costs while maintaining accuracy.

What It Means for Everyday Users
For consumers, ASR has already become a natural part of daily routines. Voice assistants control homes, search the web, and type messages. Smart devices now recognize different accents and adapt to personal speech patterns. However, users should be aware that accuracy drops in noisy environments and with less common dialects. Knowing this helps set realistic expectations.
Privacy is another point to consider. Many cloud based systems send audio to external servers for processing. Users who want more control should look for providers with clear encryption standards and transparent privacy policies. Offline systems are an option, though they often sacrifice some accuracy for data security.
Practical Tips for Better ASR Results
To get the most from ASR technology, there are simple steps users can follow:
- Speak clearly and avoid overlapping voices when possible.
- Use high quality microphones, as hardware can change accuracy levels by over 15%.
- Train the system with your voice if customization is offered.
- Review transcripts regularly to catch mistakes and improve future accuracy.
- In multilingual environments, choose solutions that are trained on diverse datasets rather than just one dominant language.
These practical habits reduce frustration and maximize the benefits of speech technology.
Trends That Will Shape the Next Decade
Looking ahead, several trends will define ASR. The first is the deeper integration with conversational AI. Systems will not only transcribe but also understand meaning and respond with context. Platforms such as Graphlogic Generative AI and Conversational Platform already point in this direction. The second trend is efficiency. Researchers are building architectures that require less power, making ASR more accessible and sustainable. The third trend is multilingual mastery. Companies are racing to expand dialect and accent support, making systems useful across borders.
By 2030 the global ASR market is expected to exceed $50 billion. Growth will come from healthcare transcription, enterprise analytics, and consumer devices. Businesses that act early will capture the most benefits, while consumers will gain access to smarter and more accurate assistants.

Why Understanding the Past Matters
Studying the history of ASR is not only academic. It teaches us why current systems perform the way they do. It explains why accuracy is so high in controlled settings but still falls in noisy rooms. It also shows why deep learning was the necessary step after HMMs and trigram models. By seeing how each problem was solved in the past, we can predict where innovation will focus next.
Final Thoughts
The journey of ASR is a story of persistence and innovation. From Audrey in 1952 to neural networks in the 1980s to deep learning today, the technology has steadily moved closer to natural human interaction. It is now central to both consumer life and enterprise operations. The next stage will likely deliver systems that not only transcribe words but also understand intent, emotion, and cultural nuance.
For businesses, the advice is clear. Start small with APIs if budgets are limited. Monitor performance in your real environment, then scale when ready. For individuals, use ASR with awareness of its strengths and weaknesses. For developers, keep an eye on efficient architectures and multilingual research.
In short, automatic speech recognition is no longer a futuristic experiment. It is a practical, evolving tool that will keep shaping communication, productivity, and even human relationships for decades ahead.
FAQ
ASR converts speech into text. Voice recognition identifies a speaker’s identity. They are related but not the same.
Modern deep learning systems achieve word error rates below 5% in controlled environments. Accuracy drops in noisy conditions or with strong accents.
Accents involve different phonetic structures and rhythm. Models trained on one accent do not generalize well. More diverse datasets are needed.
Yes, but accuracy is often lower. Offline models are smaller due to device limitations. Cloud based solutions are more accurate because they use large models.
It depends on the provider. Enterprises should check encryption standards and compliance with data regulations. Some solutions allow on premise deployment for higher security.