

In 2025, demand for accurate speaker recognition in transcription is up over 60% since 2022. From healthcare to legal tech, knowing who spoke and when is critical. The solution is speaker diarization.
It separates voices in audio, making transcripts clearer and more useful. This is essential for call centers, medical records, voicebots, and media production.
This guide explains how it works, why it matters, how to measure it, and how to choose the right tool for your needs.
What Speaker Diarization Really Does and Why It Matters
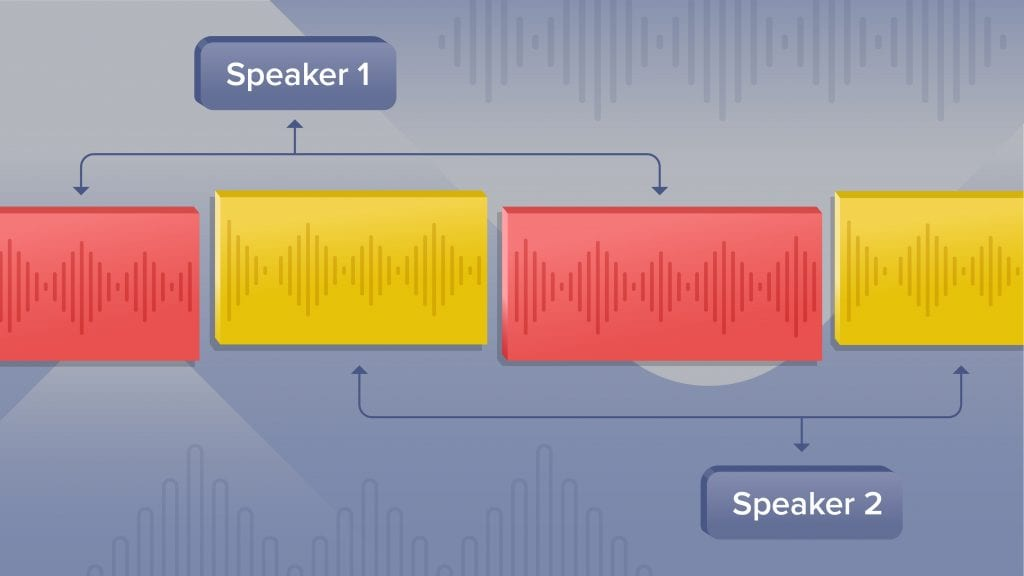
Speaker diarization is the process of identifying distinct voices in an audio recording and labeling them consistently throughout the transcript. This lets you track each speaker’s contribution with clarity. It is not just transcription. It is transcription that knows who is talking. In 2025, diarization accuracy is more important than ever because most voice recordings involve more than one speaker, often in unpredictable conditions.
Let’s say you are analyzing a panel discussion with four guests, all sharing one microphone. Basic transcription will not tell you who said what. That is where diarization changes the game. It assigns each voice a consistent label so that the resulting transcript becomes searchable and useful. This is essential for compliance in legal or financial meetings, and it also enables faster reviews and AI analysis.
What makes speaker diarization different from channel diarization is its flexibility. Channel diarization only works when each speaker has a separate microphone. But in the real world, especially in healthcare or education, that is rarely the case. Speaker diarization uses audio alone to figure out which voice belongs to whom, even when recorded on a single device. This makes it practical for mobile clinics, Zoom calls, wearable tech, and remote interviews.
For a deeper technical reference, the IEEE tutorial on speaker diarization offers solid insights on the evolution of its components.
The Core Components That Power Speaker Diarization
Modern diarization systems are built from several machine learning components that work in sequence. Each one has a job that contributes to accurate speaker separation. Let’s break it down with current examples.
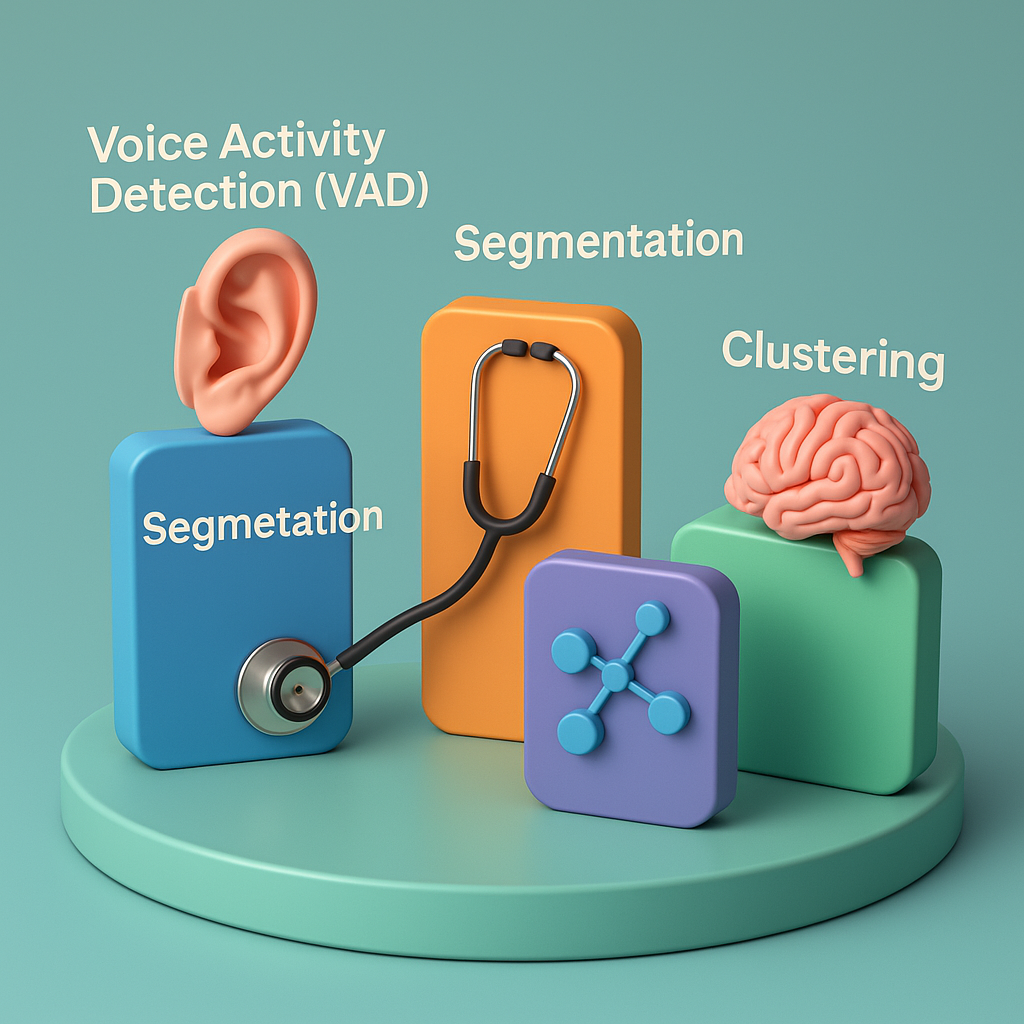
Voice Activity Detection (VAD) is the first layer. It filters out silence and background noise, passing only actual speech to the next stages. In busy environments like hospital rooms or subway stations, this step ensures the system focuses on relevant audio. A good VAD system can handle over 90% accuracy in noisy conditions when trained on diverse datasets.
Segmentation follows VAD. It breaks the filtered speech into smaller units. Earlier systems used fixed time windows, but that often cut speakers mid-sentence. Newer models use deep neural networks that learn to recognize speaker change points dynamically. This makes segmentation more natural and reduces fragmentation in conversations.
Speaker Embeddings transform each segment into a compact mathematical representation. These are called x-vectors or d-vectors. They capture unique vocal traits of each person. In top-tier systems, embeddings are trained on more than 100,000 speaker samples across 80 languages. That helps the model generalize well and adapt to unknown speakers and accents.
Clustering is the final step. It groups embeddings that represent the same voice using algorithms such as spectral clustering or agglomerative hierarchical clustering. High-end systems tune this step carefully to distinguish even subtle vocal differences such as regional accents or speech disorders.
All these layers must work together seamlessly. A weak VAD or a poorly trained embedding model will cause downstream errors. To minimize such issues, systems often include feedback loops and error correction layers. The goal is not perfection but usability. A diarization system that achieves below 10% error in real-world audio is considered reliable by industry standards.
How Speaker Diarization Improves Automated Transcription Workflows
Adding speaker diarization to an automated speech recognition (ASR) system improves transcript clarity in multi-person recordings. This is not just about labeling. It impacts how data is used, shared, and analyzed. In 2025, more than 40% of enterprises using ASR tools also report incorporating diarization to meet documentation and compliance standards.
Here are some common examples:
- In legal depositions, it enables attribution of claims to specific individuals
- In medical consultations, it helps separate physician instructions from patient history
- In customer service calls, it clearly distinguishes between agents and callers
- In classroom recordings, it identifies instructor responses versus student questions
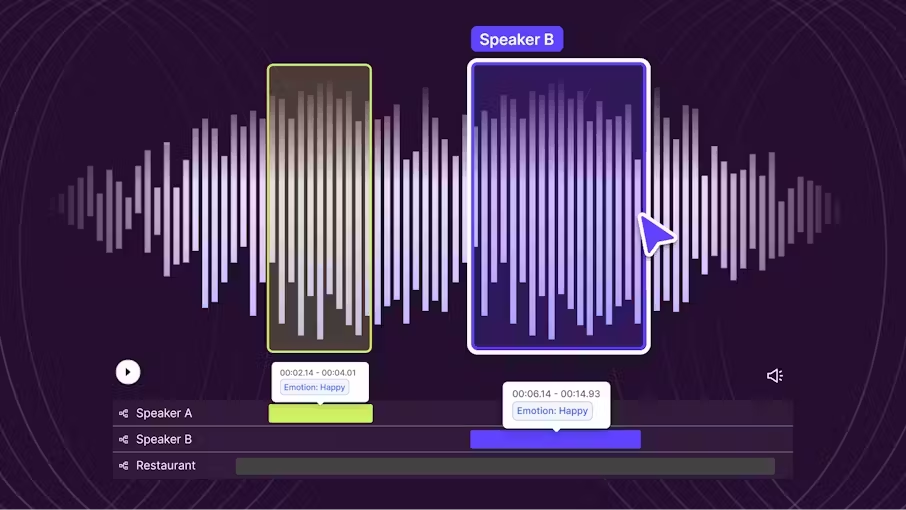
Without diarization, the transcript becomes a blur of unmarked dialogue. This leads to confusion, legal risk, and miscommunication. With diarization, the system can support downstream tasks such as sentiment detection, action item extraction, or training simulations.
Organizations using diarization in voice analytics report a reduction in review time of up to 30%. This also supports better model training for AI assistants and smarter search within large audio archives.
The Mayo Clinic study explores the clinical implications of accurate speaker separation.
Real-World Applications Across Industries
The use of speaker diarization has expanded rapidly across sectors. In 2025, the most active areas include healthcare, customer support, law enforcement, education, and media. Each of these industries benefits from improved transcription clarity and contextual accuracy.
In media production, speaker separation allows editors to navigate large podcast or documentary recordings faster. Instead of scrubbing through hours of audio, they can jump directly to specific guest segments.
In customer support, diarization improves training and quality control. Managers can review agent interactions by speaker and analyze outcomes. This also feeds into better voicebot training, especially in multi-person environments like shared households or group bookings.
In legal and compliance fields, diarization is critical for verifying who agreed to what. It supports audits and dispute resolution with clear attribution. Some financial firms now require diarization as part of call archival policies.
Educational institutions use it to index lectures, separate discussion sections, and enhance transcripts for accessibility. In hybrid classrooms, this makes reviewing content easier for students and instructors alike.
In healthcare, diarization is used in telehealth, surgery briefings, and mental health assessments. It improves accuracy in clinical notes and reduces the chance of transcription mix-ups between patients and clinicians.
To test speaker separation in your application, you can try the Graphlogic Speech-to-Text API which supports real-time diarization even in noisy and multilingual settings.
Measuring Effectiveness with Real Metrics
Two main metrics are used to assess diarization accuracy. These are Time-based Diarization Error Rate (tDER) and Time-based Confusion Error Rate (tCER). Understanding these metrics helps evaluate system performance with precision.
tCER measures how often speech segments are assigned to the wrong speaker. If a 60-minute recording has 6 minutes of incorrectly labeled speech, the tCER is 10%. This is useful for checking speaker consistency.
tDER is broader. It includes false positives (noise identified as speech), missed speech (not labeled), and confusion errors. tDER gives a full picture of how reliable the diarization system is. An acceptable tDER for most applications is between 8% and 12%.
For comparison, systems used in clinical transcription must aim for a tDER below 10% to meet electronic health record standards in the United States and Europe. Custom tuning and speaker model training can reduce tDER further for enterprise use.
The NIST guidelines explain how these rates are calculated and used in government-standard testing.
New Technologies Driving the Best Systems
As of 2025, top diarization platforms use deep neural networks to train speaker embeddings that work across diverse environments. These systems require no prior information about how many speakers are present. This makes them well suited for real-time use in podcasts, debates, and interviews.
They also support real-time feedback, which is essential in online classrooms or telehealth systems. Another trend is tighter integration between diarization and transcription engines. When speaker detection is embedded directly into the ASR pipeline, the result is more accurate and efficient.
Graphlogic Generative AI offers an example of such integration, where diarization feeds into emotion detection and intent tracking. This unlocks advanced applications in education, healthcare, and sales enablement.
Top-performing systems now handle speaker counts from one to sixteen dynamically, work in 80 or more languages, and can adapt to accent variation without requiring manual adjustment. This makes speaker diarization viable at scale for multinational deployments.
Tips for Implementing Speaker Diarization in Your Workflow
If you plan to integrate speaker diarization into your voice system, here are key factors to consider:
- Choose systems that support both real-time and offline transcription
- Test with your actual audio types, such as call center recordings or lectures
- Review error rates regularly, especially tDER, to maintain quality
- Select models that support your target languages and speaker counts
- Adjust clustering settings for overlapping speech if that occurs often

Always start with pilot tests. This lets you tune speaker embedding and segmentation models before full-scale deployment. Do not rely on benchmarks from lab data alone. Real-world audio introduces challenges like background noise, microphone inconsistency, and varied speech patterns.
Also, consider how speaker-labeled transcripts will be used downstream. If they feed into training systems or compliance logs, diarization quality becomes a critical asset.
You can explore synthetic voice generation that matches diarization output using the Graphlogic Text-to-Speech API, which can produce clean, speaker-tagged audio for training or accessibility.
Final Thoughts
In 2025, speaker diarization is no longer a niche tool. It is a necessary technology for any organization working with voice content that involves more than one person. Whether for clarity, compliance, training, or accessibility, knowing who said what is not optional.
The best way to get started is by testing diarization on real data. The difference in clarity and utility can be dramatic. And in many industries, it is becoming a requirement rather than a bonus.
For deeper applications such as multilingual real-time analytics or conversational AI, diarization is the bridge between raw audio and meaningful data.
FAQ
Yes. Modern systems can identify different speakers even from a single audio channel. This is common in mobile recordings and video calls.
Most commercial systems support between 2 and 16 speakers dynamically. For larger meetings, custom tuning may be required.
Overlapping speech remains one of the hardest challenges. However, recent models can now separate overlaps with over 70% accuracy.
Yes. Real-time diarization is now supported by advanced APIs, especially in platforms that combine ASR and speaker modeling.
Cloud-based APIs typically charge per minute. Costs range from $0.02 to $0.10 per minute depending on volume and features.