

In 2025 the global NLP market reached about $77 bn and is expected to grow at more than 26 % annually through 2030. The healthcare NLP segment was valued at $7.76 bn in 2025 and is forecast to reach $58.8 bn by 2034. These numbers are not abstract. They reflect real adoption of AI in hospitals, research labs and pharmaceutical companies. Growth is driven by digitalization of health records, demand for real-time patient insights and pressure to reduce costs. The scale of text produced daily by healthcare professionals makes manual analysis impossible. Topic modeling with advanced methods like BERT offers a practical way to surface structure in this data.

What BERT Topic Modeling Brings to Text Analysis
BERT stands for Bidirectional Encoder Representations from Transformers. It reads text in both directions, creating embeddings that capture semantics beyond single words. This is important in medicine, where terms like “positive” can mean reassuring in one context and dangerous in another. Classical models like LDA rely on word counts and co-occurrence. They miss such nuance. A 2025 comparative study on opioid related heart risk in women found that BERT based topic modeling produced compact, interpretable clusters, outperforming LDA in clarity. This means clinicians and researchers can navigate growing text corpora with greater confidence and less manual effort.
How BERTopic Fits into Practice
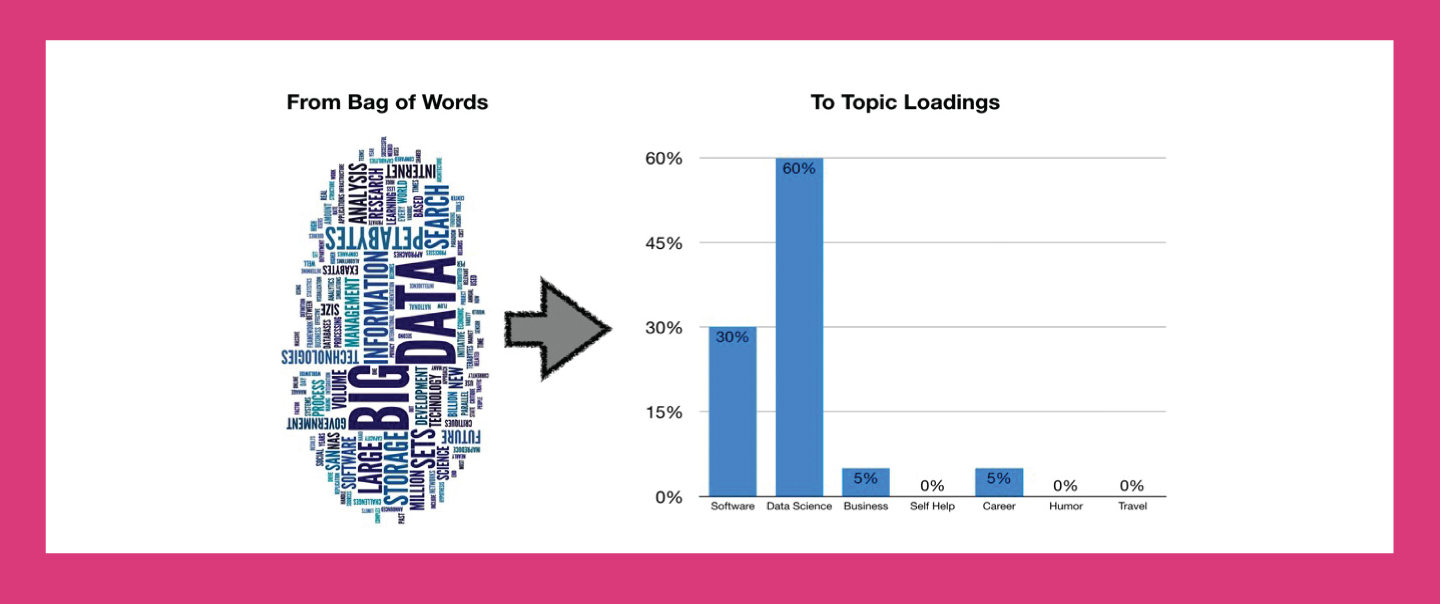
BERTopic is an open-source Python library built to turn BERT embeddings into structured topics. Its workflow starts with embeddings, applies UMAP for dimensionality reduction, then uses HDBSCAN to cluster documents. Finally, it extracts key terms with class based TF-IDF. This combination makes outputs both precise and interpretable. In practice researchers use it to track themes in patient feedback, literature reviews and trial data. Healthcare providers apply it to detect recurring concerns, from waiting times to treatment side effects.
Visualization and Interpretation Made Clear
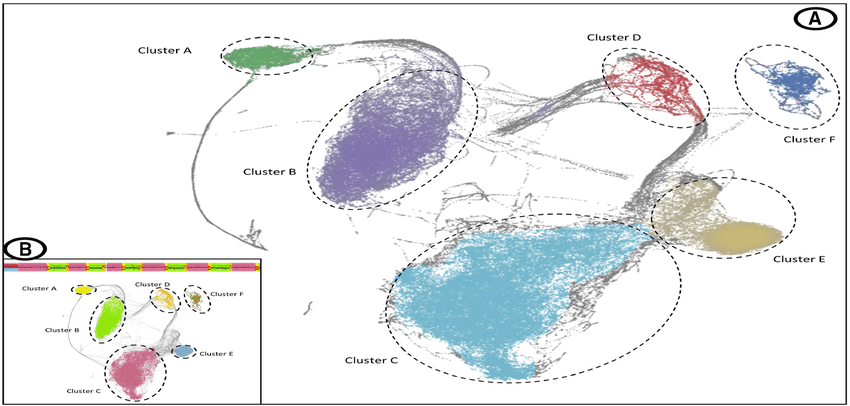
Visualization makes model outputs easier to use and explain. UMAP scatter plots shrink high dimensional data into simple two dimensional maps. Each point represents a document, and color coding separates clusters. Analysts can immediately see whether clusters are compact or diffuse. Documents that do not fit into any cluster are usually labeled as topic minus one. These may be outliers, anomalies, or rare records that need extra review. In medical datasets, such outliers can sometimes reveal rare conditions or errors in data entry.
Interpretation is not limited to visual plots. Analysts also study coherence scores, which measure how well the words in each topic fit together. A high coherence score signals strong internal consistency, meaning the terms describe one clear theme. Low coherence scores indicate confusion or noise, which reduces trust in findings. Coherence evaluation is essential when medical decisions may follow. Good practice includes combining visualization, coherence scoring, and manual review. That ensures the topics are not only statistically correct but also clinically relevant. Visualization gives decision makers a clearer path from complex data to practical insight.
Trends and Forecasts for Healthcare NLP
The healthcare NLP market is expanding fast. It was $7.76 bn in 2025 and is forecast to reach $58.8 bn by 2034. Another analysis projects $5.18 bn in 2025 rising to $16 bn by 2030 with a 25 % CAGR. This growth is driven by hospitals adopting NLP for record management, insurers using AI for claims, and researchers mining scientific text at scale.
Hospitals are piloting AI tools that generate discharge summaries automatically. This reduces administrative bottlenecks, cuts delays, and allows clinicians to focus on patients. Public agencies are also testing NLP to track outbreaks and population health trends. At the same time, surveys show that while doctors recognize AI’s value, patients remain cautious. Trust is fragile when it comes to sensitive health data. Building transparency, ensuring clear audit trails, and showing measurable outcomes are essential steps for adoption. Over the next decade, healthcare NLP will likely move from pilot projects into core hospital systems, creating measurable time and cost savings.

Real-World Examples in Healthcare
In the UK NHS, AI systems draft discharge summaries automatically. Doctors only review and approve the drafts, reducing paperwork time sharply. This saves hours for each clinician weekly and speeds patient flow. It also shows how NLP can manage both structured and unstructured records without creating extra work.
On the patient side, AI driven platforms support preparation for surgery and recovery afterwards. These tools provide personalized plans based on patient data and global medical evidence. Reports show such platforms cut complications, lower readmission rates, and reduce overall costs. Some systems even track patient progress in real time and adjust guidance accordingly. These examples highlight the dual role of NLP. It can support clinical efficiency, making hospitals work faster, and at the same time it can improve patient outcomes directly. Together, these benefits demonstrate why adoption continues despite cost and trust concerns.
Examples of Model Innovation
Domain specific BERT variants are reshaping medical NLP practice. Bioformer is a compact biomedical BERT with 60 % fewer parameters. It runs two to three times faster, yet achieves accuracy close to full BERT. This efficiency makes it practical for use with very large biomedical corpora such as PubMed.
ClinicalBERT was trained on over 1.2 bn words from more than 3 million clinical notes. It improves performance in tasks such as outcome prediction, treatment recommendation, and phenotype classification. Both models show that general NLP tools adapt better when tuned for medical data. These innovations also reduce infrastructure needs and speed up experimentation. The result is more accessible AI for hospitals and research institutions. As specialized variants expand, BERT topic modeling will become more efficient, scalable, and domain aware. That makes it a realistic option even for organizations with limited technical budgets.
Challenges and Expert Tips for Better Models
Large BERT models demand GPUs and strong cloud infrastructure, which increases costs significantly. Training and inference with full size BERT can take hundreds of GPU hours, which translates into thousands of dollars for research institutions and startups. One practical solution is to use compact variants such as Bioformer or DistilBERT. Bioformer reduces parameters by 60 % yet remains close in accuracy and runs up to three times faster, making it feasible for large biomedical databases. DistilBERT cuts model size nearly in half and is well suited for quick experimentation. Both offer a balance between performance and affordability.
Another critical step is thorough data cleaning. Clinical text is often messy, filled with abbreviations, inconsistent spellings, and irrelevant symbols. Expanding abbreviations, normalizing spelling, and removing extra symbols improve input quality. Preprocessing directly affects topic coherence, since noise in data leads to poorly defined clusters. Hospitals that applied NLP with strict preprocessing reported up to 30 % improvement in topic quality compared with raw text input.
Tuning parameters for UMAP and HDBSCAN is equally important. Too much dimensionality reduction with UMAP removes valuable nuance, while too little leaves too much noise. HDBSCAN requires careful setting of minimum cluster size. If set too small, topics become fragmented, and if set too large, distinct themes merge together. Good practice is to experiment with ranges and validate results against coherence scores and domain expertise.
Domain specific embeddings such as ClinicalBERT add further precision. Trained on over 1.2 bn words from millions of patient records, ClinicalBERT captures medical semantics much better than general models. Using such embeddings has been shown to improve accuracy in tasks like diagnosis prediction and treatment recommendation. Outliers must also be managed carefully. Some represent noise or incomplete text, but others can reveal rare diseases or early signs of risk that generic clustering would overlook. Removing them blindly risks losing valuable insight.
For deployment, topic modeling results should integrate smoothly into workflow platforms. The Graphlogic Generative AI & Conversational Platform allows teams to plug NLP outputs into clinical decision support or patient-facing applications. Communication of insights is another important layer. Instead of static dashboards, findings can be delivered through natural speech using the Graphlogic Text-to-Speech API. This is useful for patient engagement, accessibility, and real-time alerts in healthcare environments.
Expert checklist for stronger models:
- Use compact BERT variants to cut costs and speed up workflows
- Apply robust preprocessing to handle abbreviations and normalize clinical terms
- Tune UMAP and HDBSCAN parameters iteratively with coherence validation
- Prefer domain specific embeddings like ClinicalBERT for medical text
- Examine outliers carefully, as they may reveal rare but valuable insights
- Integrate outputs with workflow and communication platforms for practical impact
Together, these best practices make BERT topic models more accurate, efficient, and trustworthy. They also ensure that advanced NLP remains not only a research tool but a practical component of healthcare systems.
FAQ
The market was valued at $7.76 bn in 2025 and may reach $58.8 bn by 2034. Another forecast sees $5.18 bn in 2025 rising to $16 bn by 2030.
Yes. The NHS tests AI tools to automate discharge summaries.
Bioformer is smaller and faster with high accuracy. ClinicalBERT offers higher precision in clinical tasks.
Clinicians show strong trust in AI, but patients are cautious. A Philips survey found transparency and demonstrated outcomes are critical to acceptance.