

Voice AI has reached a point where accuracy alone is no longer enough. In 2025, performance is now measured by responsiveness. The systems that feel fast win trust, adoption, and long-term loyalty.
People use voice assistants across many domains including healthcare, banking, retail, and logistics. In each of these settings, users expect near-instant responses. That expectation is now shaping how AI platforms are designed and deployed.
According to MLCommons, systems that maintain sub-500 millisecond latency see a 43% improvement in retention compared to slower models. Voice products from large tech companies such as Google, Apple, and Amazon have adopted that threshold as a baseline standard in 2025.
Voice AI Trends and Forecasts for 2025
Below are the key trends shaping the current landscape and where things are headed next.
Leading Trends in Voice AI
- Latency is now a baseline KPI. In 2025, latency is not a backend detail. It is a customer-facing metric. Companies now treat sub-500 millisecond response time as mandatory for most applications. Real-time dashboards display latency alongside uptime, and executive teams track it alongside retention and conversion rates.
- Streaming-first architecture becomes the standard. Instead of waiting for a full response, modern voice AI systems now stream tokens and audio back to users in real time. This allows systems to “speak while thinking,” dramatically improving responsiveness. It also improves perceived speed, even when backend inference is heavy.
- Edge and hybrid deployments dominate new rollouts. Voice AI is shifting from cloud-only to edge-plus-cloud infrastructure. In healthcare, automotive, and logistics, edge nodes allow instant decisions near the user, with fallback processing handled in the cloud. This setup reduces latency and improves data privacy compliance.
- Specialized hardware is standard in production stacks. GPUs such as NVIDIA H100 and Google TPUs are now built into enterprise AI deployments. These chips support fast inference and support model architectures built for speed. Companies are also investing in ASICs and neuromorphic processors for voice-specific workloads.
- Text-to-speech and voice cloning shift to real time. The demand for instant voice synthesis has grown sharply. Call centers, medical assistants, and even educational apps are using real-time voice generation. Platforms like the Graphlogic Text-to-Speech API are designed to meet this demand with sub-300 millisecond response times.
- Synthetic voice personalization gains ground. Brands and healthcare systems increasingly use personalized voice agents. These systems adapt tone, speech rhythm, and vocabulary based on user preferences. This trend is driven by better user satisfaction scores and reduced cognitive fatigue in repeat use.

Forecasts for the Voice AI Market
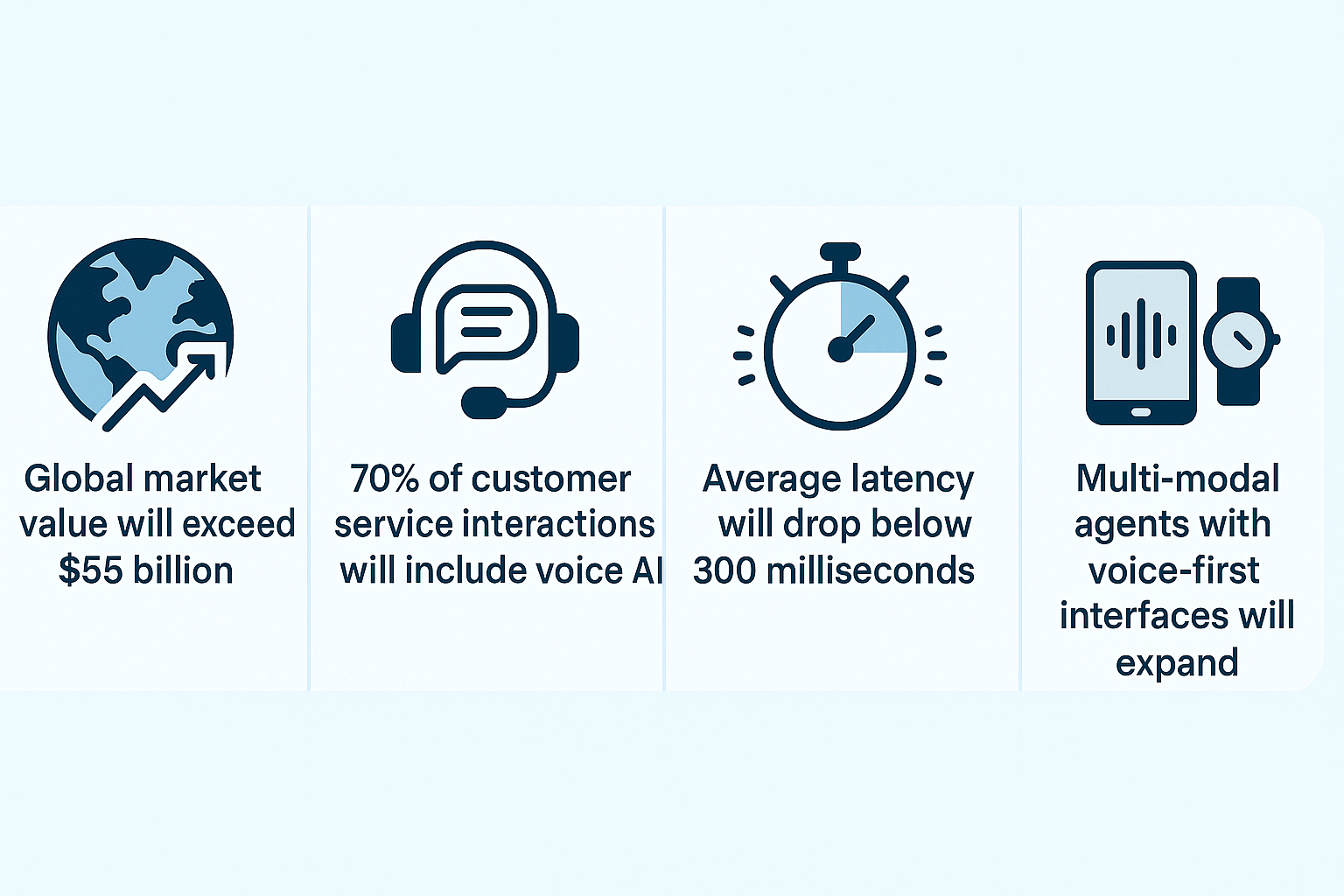
- Global market value will exceed $55 billion. According to Statista, the voice AI market is expected to grow beyond $55 billion by the end of 2025. This is driven by growth in Asia, rising demand for on-device assistants, and healthcare deployments.
- 70% of customer service interactions will include voice AI. Gartner projects that by Q4 2025, 7 out of 10 service interactions will include voice automation. This includes both agent-assist tools and fully autonomous responses.
- Average latency will drop below 300 milliseconds in top platforms. Internal benchmarks from Amazon, Microsoft, and Google show consistent improvements in sub-300 millisecond latency as a product goal. This sets the new performance baseline for competitive AI deployments.
- Real-time voice analytics adoption will triple. Tools that track voice tone, sentiment, and intent in real time will be standard in finance, HR, and support. These insights are used not just for compliance but to adjust AI behavior dynamically.
- Multi-modal agents with voice-first interfaces will expand. Voice AI is moving beyond smart speakers. It now powers kiosks, vehicle interfaces, wearables, and virtual assistants inside apps. Multi-modal AI that starts with voice and integrates visual cues is set to dominate product design across industries.
Voice AI is no longer just a feature. In 2025, it is the engine behind more responsive, personalized, and scalable human-machine interaction. Teams that adapt to these trends and invest in latency-first design will lead the way in trust, usability, and growth.
Speed and User Trust Go Hand in Hand
When users speak to a machine, their expectations are shaped by how they talk to people. Most human conversations involve natural pauses of about 200 milliseconds. Voice AI must match or beat that to feel effortless. Delays longer than that trigger discomfort and make the interaction feel less intelligent.
Trust in AI begins with responsiveness. If a voice system takes too long to reply, users assume it misunderstood the request or is still “thinking.” This slows down interaction and makes users reluctant to continue. In contact centers, that leads to dropped calls and poor customer reviews. In healthcare, it makes digital assistants less usable during fast-paced clinical conversations.
A 2025 MIT CSAIL study found that cognitive strain increases by 27% when AI voice systems respond after 500 milliseconds. This type of delay is not only noticeable, it changes user behavior. People become hesitant, shorten their speech, or give up altogether.
On the other hand, fast systems create a sense of fluency. A platform like the Graphlogic Generative AI & Conversational Platform supports real-time interaction under 300 milliseconds, which keeps dialogue fluid and natural. This directly increases user confidence and willingness to use AI more often.
The faster the system, the more helpful it feels. And the more it feels helpful, the more users will rely on it regularly. That is why trust and latency are so tightly linked.

Technical Benchmarks That Actually Matter
When it comes to evaluating speed in voice AI, only a few metrics offer real insight. These include latency, Time-to-First-Token (TTFT), Tokens Per Second (TPS), and throughput. Each one reflects a different stage of system performance and responsiveness.
Latency measures how long the system takes to begin processing and generate a response. This includes audio capture, transcription, model inference, and response generation. For a good experience, latency should stay under 500 milliseconds.
TTFT focuses on the time from user input to the system’s first spoken or displayed output. This is critical because users care most about when they first hear a reply. In fast systems, TTFT is under 250 milliseconds. If it reaches 600 milliseconds or more, dropout rates increase sharply.
TPS measures how quickly a model generates output once the first token appears. This reflects backend optimization. Systems with more than 50 tokens per second feel fast enough for spoken interaction. Lower values create awkward silences.
Throughput refers to how many conversations a system can handle simultaneously without delay. As user volume grows, good throughput ensures consistent performance even under peak load.
MLPerf provides benchmark tools that simulate real-world use cases for these metrics. If a system is slow under load, it will not scale well in production. For this reason, performance engineers often test their models using real traffic or live conversations during pilot runs.
Developers building live applications often use services like the Graphlogic Speech-to-Text API to minimize transcription delays. This API maintains accuracy while operating well under the 300 millisecond target even when multiple users are connected at once.
To stay competitive, teams should define clear targets for each of these metrics and monitor them regularly in production environments.
Infrastructure That Keeps AI Fast at Scale
Building fast voice AI does not stop at the model level. Infrastructure has an equal impact. As demand increases, systems must remain fast without manual tuning. That requires thoughtful architecture, edge deployment, and automatic scaling.
First, load balancing is essential. Without it, requests may overload a single server while others sit idle. This creates uneven response times that are hard to detect during testing but frustrating in production. Load balancing distributes traffic and reduces delays under peak conditions.
Second, horizontal scaling allows systems to spin up new instances when traffic spikes. This prevents slowdowns caused by resource limits. In platforms handling millions of voice queries per day, this scaling must happen automatically based on usage trends.
Third, edge computing is increasingly common. It brings the model closer to the user by processing audio near the data source. In practice, this reduces latency by 100 to 200 milliseconds. For mobile apps and global services, edge nodes are a low-cost way to guarantee responsiveness.
Fourth, dynamic resource allocation improves real-time processing. Instead of assigning fixed compute power to each request, modern systems allocate GPU or TPU resources based on complexity and model size. This makes it possible to run large models efficiently without delay.
One leading example is Deepgram’s edge deployment model, which delivers latency under 250 milliseconds while supporting thousands of parallel sessions. Their system uses regional nodes and caching to reduce response time globally.
Monitoring is also essential. Engineering teams must track live latency and throughput using real data. Most systems log TTFT and TPS by location, device type, and time of day. These insights allow real-time tuning and long-term improvements.
Without this infrastructure, even the best model will struggle under load. Fast systems begin with fast architecture.
What Happens When Voice AI Is Too Slow
Speed problems are not just annoying. They break the user experience and reduce the value of AI systems. Many real-world failures can be traced to latency issues that went unmonitored or were underestimated.
When a user experiences delay, the interaction feels unnatural. This leads to dropped sessions, reduced satisfaction, and lower feature usage. In some industries, it even causes financial loss.
For instance, in banking, fraud detection systems that rely on voice verification cannot afford latency. A 300 millisecond delay can allow malicious behavior to go unnoticed. In a healthcare setting, delayed transcription may result in incomplete records or missed critical information. This leads to safety concerns and legal liability.
Contact centers also suffer. When AI takes too long to respond to a customer, the caller may hang up or ask to speak with a human. Studies by Forrester in 2025 show that 1 in 4 callers abandons a session if they wait more than 2 seconds for a spoken response. That delay also decreases agent efficiency, as staff must re-engage with frustrated users.
The cost of slow AI also affects brand reputation. Users remember delays, especially when voice systems are positioned as modern tools. Lag creates a sense of unreliability and lowers adoption across the platform.
The solution is to monitor latency closely and fix bottlenecks early. User behavior often provides the first sign of problems. Spikes in dropout, incomplete queries, or low engagement can all signal growing speed issues.

Real-World Examples That Prove Speed Wins
The best way to understand the power of speed in voice AI is to look at where it already works. These real examples show that when systems respond fast, performance improves across the board.
- GPT-4o, a recent language model, responds in 232 milliseconds. That allows it to hold real-time conversations that feel natural. This is critical for education apps and assistive technology, where delay breaks learning flow.
- Tesla’s Full Self-Driving (FSD) system processes 2 300 frames per second. This is essential for safety. By reacting in under 100 milliseconds to road data, it avoids collisions and supports real-time decisions.
- Deepgram Nova-2 sets the benchmark in transcription. It converts voice to text up to 40 times faster than older systems. This allows customer support teams to process live calls, generate summaries, and respond during the conversation.
- High-frequency trading firms use AI systems that make financial decisions in less than 1 millisecond. This speed captures market opportunities that slower competitors cannot even see.
- Healthcare applications now use AI documentation tools that transcribe clinician speech instantly. This saves doctors 2 to 3 hours per week. That time is then used for patient care, improving satisfaction and outcomes.
These examples span different industries, but the pattern is the same. Speed improves accuracy, satisfaction, and productivity. Slower systems simply cannot compete.
FAQ
Aim for under 300 milliseconds. Anything under 500 milliseconds is acceptable but less optimal.
Yes. A delay of even 200 milliseconds can reduce voice commerce conversion by up to 9%.
Not always. But in voice AI it reduces delay and makes speech interfaces feel more natural.
Optimize your model pipeline, cache frequent phrases, and use GPU inference.
Yes. Perception tests show users find responses over 300 milliseconds noticeably less smooth.