

Accurate transcripts are critical across sectors like healthcare, legal services, education, and customer support — but they’re especially vital when conversations involve multiple people. Unfortunately, standard transcription often collapses overlapping dialogue into a single block of text, stripping away who said what. This creates confusion and undermines the usefulness of the transcript for compliance, insight generation, or simple readability.
That’s where speaker diarization becomes indispensable. It solves the “who spoke when” challenge by labeling sections of audio with speaker identities. Whether it’s a business meeting, an interview, or a phone consultation, diarization provides structure to spoken content, enabling richer insights and automation downstream.
Today, this technology is driving innovation in fields like remote healthcare, AI-driven meeting assistants, call center analytics, and voice-enabled learning platforms. If your work involves speech data — even casually — understanding diarization is key to unlocking its value.

What Is Speaker Diarization?
At its core, speaker diarization is the automated process of identifying and labeling individual speakers within an audio stream. It’s a feature commonly integrated into speech-to-text systems, transforming otherwise flat transcripts into organized, multi-speaker records. Rather than a jumbled wall of text, diarized transcripts might look like this:
Speaker 1: I need to reschedule my appointment.
Speaker 2: Sure, how about next Thursday?
This labeled structure makes conversations easy to follow and enables further analysis.
Importantly, diarization works on single-channel audio, where all voices are mixed together. This is common in real-world recordings — think phone calls, online meetings, or bodycam footage. In contrast, channel-based diarization, which separates speakers via individual microphones, is far less practical for everyday use cases.
Diarization adds tremendous value in dynamic, spontaneous conversations, where people interrupt, speak quickly, or share similar tones. It helps disambiguate the flow of dialogue and captures the rhythm of natural interaction — essential for accuracy and context.
For foundational research, see the NIST Rich Transcription Evaluation Project.
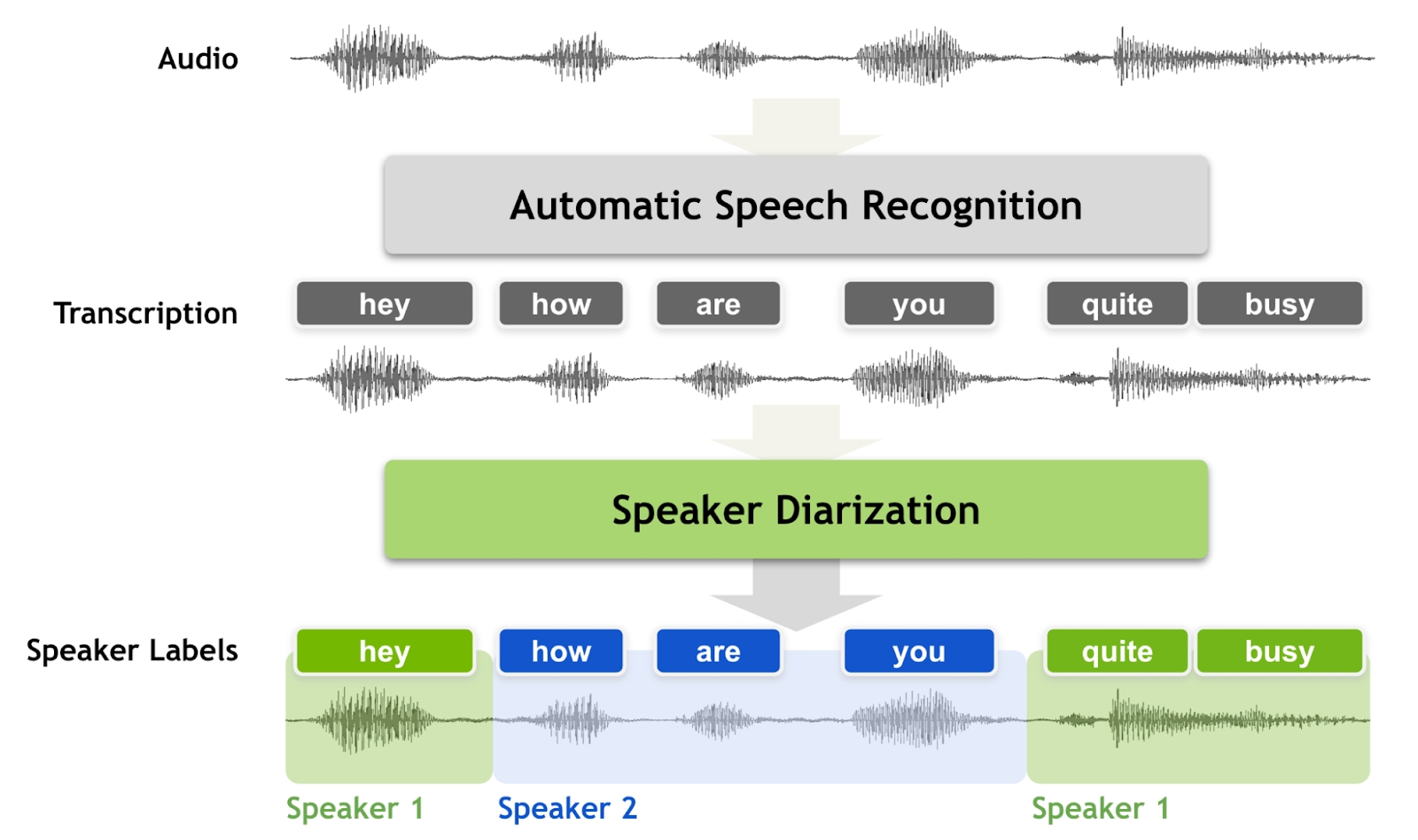
How Does Speaker Diarization Work?
Speaker diarization is built around a multi-step process designed to break down complex audio into manageable, speaker-attributed segments. Each step plays a critical role in producing reliable results:
1. Voice Activity Detection (VAD)
This stage isolates segments where human speech occurs. It removes silence, ambient noise (e.g., air conditioners or street sounds), and non-verbal cues like sighs or laughter. VAD ensures the system focuses only on meaningful audio data.
Some systems use traditional rule-based approaches, while others rely on neural models trained on diverse acoustic environments. The better the VAD, the less junk gets passed on to the next stages.
2. Segmentation (Speaker Change Detection)
Next, the audio is analyzed to detect transition points — places where one speaker stops and another starts. This is challenging, especially in overlapping speech, group conversations, or recordings with poor audio quality.
State-of-the-art systems apply advanced signal processing and deep learning models that can detect subtle voice shifts or speaking styles, even when interruptions occur mid-sentence.
3. Representation (Speaker Embeddings)
Each audio segment is then transformed into a numerical vector (e.g., x-vector or d-vector) that encodes unique vocal features like pitch, tone, and cadence. These embeddings allow the system to compare voices and cluster segments accordingly.
For more detail, read this IEEE overview on speaker embeddings.
4. Clustering (Speaker Attribution)
Finally, embeddings are grouped using clustering algorithms such as k-means, agglomerative clustering, or newer density-based methods. Each group gets a speaker label (e.g., Speaker A, B, etc.), completing the diarization pipeline.
Together, these steps allow AI to convert chaotic real-world audio into structured, speaker-labeled transcripts — whether in real time or from stored files.
The Role of Neural Models in Speaker Diarization
In earlier systems, diarization relied on handcrafted acoustic features and basic statistical models. These approaches struggled in real-life conditions — especially with accents, background noise, or fast speaker changes.
Neural networks have transformed this landscape. Deep learning allows diarization models to:
- Extract more discriminative and robust embeddings from noisy data.
- Handle spontaneous speech with self-supervised learning on massive unlabeled datasets.
- Improve segmentation with recurrent networks that model long-term audio context.
- Leverage transformer-based models for attention across time segments.
Some models now integrate language modeling and contextual reasoning. For example, if one speaker asks a question and another responds, the system can detect turn-taking patterns and resolve ambiguities.
Microsoft’s diarization pipeline demonstrates this integration within the Azure Cognitive Services suite.

Why Is Speaker Diarization Important?
Speaker diarization adds far more than convenience — it enables entirely new workflows, automations, and insights across industries. Here’s how it translates into real-world value:
Enhanced Transcript Quality
Without diarization, transcripts become dense, contextless, and often misleading. With speaker attribution, they’re readable and mirror the structure of the original conversation — preserving meaning and emotional cues.
Actionable Intelligence
Knowing who said what enables targeted analysis. Businesses can monitor agent performance, sales teams can track pitch effectiveness, and researchers can analyze group dynamics in qualitative interviews.
Legal and Regulatory Compliance
In medical, legal, or financial domains, accurate speaker labeling is essential. Diarization ensures that records reflect who gave consent, made decisions, or provided advice — reducing liability and aiding documentation.
Education and Accessibility
Educational institutions use diarization to build more effective learning tools. Students reviewing lectures benefit from speaker-labeled transcripts that distinguish instructor comments from peer questions — making study more efficient and personalized.
Common Use Cases for Speaker Diarization
Speaker diarization is being widely adopted across a range of industries. Here are the most impactful applications:
1. Customer Service
Tools like AWS Transcribe and Google Speech-to-Text help contact centers separate agent and customer voices to improve QA monitoring, sentiment analysis, and compliance reporting.
2. Healthcare
Graphlogic’s Speech-to-Text API supports clinician-patient diarization, allowing automated generation of EHR notes, diagnosis summaries, and secure transcripts of remote visits.
3. Education
Services that support multi-speaker transcription — such as Deepgram’s platform — help students and teachers review conversations with clear speaker separation, improving accessibility and documentation.
4. Law Enforcement
Diarization enhances clarity in legal proceedings, such as bodycam footage, interrogations, or interview recordings, making it easier to timestamp and attribute each voice for admissibility in court.
5. Sales Enablement
Tools like Chorus.ai and Deepgram-based voice stacks enable revenue teams to dissect sales calls, attributing objections and buying signals to individual participants for CRM enrichment.
Metrics for Evaluating Speaker Diarization
Two major metrics help assess diarization quality:
Time-based Confusion Error Rate (tCER)
Measures how often the system assigns a segment to the wrong speaker. Lower tCER = better speaker distinction.
Time-based Diarization Error Rate (tDER)
Includes speaker confusion, missed speech, and false positives. It’s a holistic indicator of real-world performance.
For benchmarking, refer to this comprehensive diarization metrics review on arXiv.
Comparing Speaker Diarization Tools
| Provider | Strengths | Limitations |
| Google STT | Fast, scalable, mobile-ready | Limited control over custom vocabularies |
| AWS Transcribe | Multi-speaker support, streaming-friendly | Can struggle with overlapping voices |
| Microsoft Azure | Strong UI, easy enterprise integration | May require parameter tuning for edge cases |
| Deepgram | Real-time, no need to preset speaker count | Less broad language support vs. Google |
| Graphlogic STT API | Developer-first platform, unified pipeline | Requires more custom setup for deployment |
Deepgram’s Approach to Diarization
Deepgram offers a modern, neural diarization engine that works across diverse industries and acoustic conditions. It does not require speaker count in advance, which makes it ideal for real-time conferencing and dynamic meetings.
Core advantages include:
- Multilingual diarization
- Real-time and pre-recorded support
- Robust to noise, accents, and fast-paced speech
- Compatible with streaming pipelines and custom workflows
Deepgram’s diarization is trained on domain-diverse datasets — from podcasts and lectures to legal audio — ensuring higher generalization across sectors.

Challenges and Limitations of Speaker Diarization
Despite significant advancements, diarization isn’t perfect. Key challenges include:
- Overlapping Speech: When multiple people talk at once, it’s difficult to separate voices cleanly — especially in real time.
- Voice Similarity: Systems may confuse speakers with similar pitch, gender, or accents, like twins or colleagues in the same region.
- Domain Drift: Models trained on call center audio may perform poorly on legal depositions or psychiatric consults.
- Privacy Concerns: Voice data requires strict control. GDPR, HIPAA, and similar regulations demand anonymization, encryption, and sometimes on-device processing.
These factors emphasize the need to evaluate diarization tools in the exact context in which they’ll be deployed.
Trends and Future Directions in Speaker Diarization
Speaker diarization is rapidly evolving. Here are five key trends shaping its future:
1. Real-Time Diarization
With growing demand for live captions, voicebots, and instant analytics, real-time diarization is becoming essential. Platforms like Deepgram and Graphlogic lead in low-latency diarization APIs.
2. Sentiment and Intent Fusion
Combining diarization with emotion detection, intent tagging, and sentiment analysis allows more contextual AI — ideal for customer success, therapy bots, and HR monitoring.
3. Domain-Specific Models
More diarization models are being trained on domain-specific corpora (e.g., legal, medical, broadcast). These tuned models outperform general ones significantly in specialized settings.
4. Unified AI Pipelines
Diarization is now part of complete speech intelligence stacks — integrated with ASR, summarization, translation, and speaker search — such as in Graphlogic’s Generative AI Platform.
5. Privacy-Preserving Architectures
Expect to see more on-device diarization, edge computing, and encrypted embeddings — critical for regulated industries and ethical AI.
FAQ
It’s the process of labeling parts of an audio by speaker.
Through detection, segmentation, voice embeddings, and clustering.
It makes transcripts more useful and enables accurate analytics.
Deepgram, AWS Transcribe, Google STT, and Graphlogic Speech-to-Text.
It depends on the environment, model training, and speaker count — but high-quality systems can reach tDER below 10%.